LLaVA-NeXT: Stronger LLMs Supercharge Multimodal Capabilities in the Wild
On January 30, 2024, we unveiled LLaVA-NeXT, a state-of-the-art Large Multimodal Model (LMM) developed using a cost-effective training method leveraging open resources. It enhances reasoning, OCR, and world knowledge across multimodal capabilities using the leading LLM of that time, Yi-34B. LLaVA-NeXT has showcased outstanding performance across various multimodal understanding tasks, even surpassing Gemini-Pro on benchmarks such as MMMU and MathVista. Recently, the community has witnessed the emergence of open-source LLM with stronger language capability, exemplified by LLaMA3 and Qwen-1.5 family. Simultaneously, there is speculation that proprietary LMMs like OpenAI GPT-V are supported with stronger LLMs such as GPT-4. This naturally raises the question: as the disparity between open and proprietary LLMs diminishes with the introduction of potent new language models, does the gap between open and proprietary multimodal models also narrow, when powered by these stronger LLMs?
Today, we expanded the LLaVA-NeXT with recent stronger open LLMs, reporting our findings on more capable language models:
- Increasing multimodal capaiblies with stronger & larger language models, up to 3x model size. This allows LMMs to present better visual world knowledge and logical reasoning inherited from LLM. It supports LLaMA3 (8B) and Qwen-1.5 (72B and 110B).
- Better visual chat for more real-life scenarios, covering different applications. To evaluate the improved multimodal capabilities in the wild, we collect and develop new evaluation datasets, LLaVA-Bench (Wilder), which inherit the spirit of LLaVA-Bench (in-the-wild) to study daily-life visual chat and enlarge the data size for comprehensive evaluation.
Open-Source Release
We open-source the LLaVA-NeXT to facilitate future development of LMM in the community. Code, data, model will be made publicly available.
Benchmark Results
| Results with LMMs-Eval | GPT4-V | LLaVA-NeXT (2024-05 Release) | LLaVA-NeXT (2024-01 Release) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Datasets | Split | Metric | Instances | Qwen1.5-110B | Qwen1.5-72B | LLaMA3-8B | Yi-34B | Vicuna-1.5-13B | Vicuna-1.5-7B | Mistral-7B | |
| AI2D* | test | Acc. | 3088 | 78.2 | 80.4 | 77.4 | 71.6 | 74.9 | 70.0 | 66.6 | 60.8 |
| ChartQA* | test | RelaxedAcc. | 2500 | 78.5 | 79.7 | 77.0 | 69.5 | 68.7 | 62.2 | 54.8 | 38.8 |
| DocVQA* | val | ANLS | 5349 | - | 85.7 | 84.4 | 78.2 | 84.0 | 77.5 | 74.4 | 72.2 |
| MathVista | test | Acc. | 1000 | 49.9 | 49.0 | 46.6 | 37.5 | 46.0 | 35.1 | 34.4 | 37.4 |
| MMBench | dev | Acc. | 4377 | 75.0 | 80.5 | 80.5 | 72.1 | 79.3 | - | - | - |
| MME-Cognition | test | Total Score | 2374 | 517.1 | 453.9 | 459.6 | 367.8 | 397.1 | 316.8 | 322.5 | 323.9 |
| MME-Perception | test | 1409.4 | 1746.5 | 1699.3 | 1603.7 | 1633.2 | 1575.1 | 1519.3 | 1500.9 | ||
| MMMU | val | Acc. | 900 | 56.8 | 50.1 | 49.9 | 41.7 | 49.7 | 35.9 | 35.1 | 33.4 |
| RealWorldQA | test | Acc. | 765 | 61.4 | 63.1 | 65.4 | 60.0 | 61.0 | - | - | 54.4 |
| LLaVA-W** | test | GPT4-Eval | 60 | 98.0 | 90.4 | 89.2 | 80.1 | 88.8 | 72.3 | 72.3 | 71.7 |
| LLaVA-Bench (Wilder) | Small | GPT4V-Eval | 120 | 71.5 | 70.5 | 71.2 | 62.5 | - | - | - | - |
| Medium | GPT4V-Eval | 1020 | 78.5 | 72.5 | 73.4 | 63.1 | - | - | - | - | |
| *Train split observed during SFT stage. | |||||||||||
| **We report the evaluation results with GPT-4-0613 on LLaVA-W. | |||||||||||
Highlights
- SoTA level Performance! LLaVA-NeXT achieves consistently better performance compared with prior open-source LMMs by simply increasing the LLM capability. It catches up to GPT4-V on selected benchmarks.
- Low Training Cost! We maintain an efficient training strategy like previous LLaVA models. We supervised finetuned our model on the same data as in previous LLaVA-NeXT 7B/13B/34B models. Our current largest model LLaVA-NeXT-110B is trained on 128 H800-80G for 18 hours.
[Fold / Unfold to see full tables for comparison with LLaVA Family and SoTA LMMs]
| Results with LMMs-Eval | Claude3-Opus | GPT4-V | Gemini 1.5 Pro | Qwen-VL Max | LLaVA-NeXT (2024-05 Release) | LLaVA-NeXT (2024-01) | LLaVA-1.5 | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Datasets | Split | Metric | Instances | Qwen1.5-110B | Qwen1.5-72B | LLaMA3-8B | Yi-34B | Vicuna-1.5-13B | ||||
| AI2D* | test | Acc. | 3088 | 88.1 | 78.2 | 80.3 | 79.3 | 80.4 | 77.4 | 71.6 | 74.9 | 54.8 |
| ChartQA* | test | RelaxedAcc. | 2500 | 80.8 | 78.5 | 81.3 | 79.8 | 79.7 | 77.0 | 69.5 | 68.7 | 18.2 |
| DocVQA* | val | ANLS | 5349 | - | - | - | - | 85.7 | 84.4 | 78.2 | 84.0 | 28.1 |
| MathVista | test | Acc. | 1000 | 50.5 | 49.9 | 52.1 | 51.0 | 49.0 | 46.6 | 37.5 | 46.0 | 26.7 |
| MMBench | dev | Acc. | 4377 | - | 75.0 | - | - | 80.5 | 80.5 | 72.1 | 79.3 | 67.8 |
| MME-Cognition | test | Total Score | 2374 | - | 517.1 | - | 2281.7 | 453.9 | 459.6 | 367.8 | 397.1 | 348.2 |
| MME-Perception | test | - | 1409.4 | - | 1746.5 | 1699.3 | 1603.7 | 1633.2 | 1510.8 | |||
| MMMU | val | Acc. | 900 | 59.4 | 56.8 | 58.5 | 51.4 | 49.1 | 46.4 | 41.7 | 46.7 | 35.3 |
| RealWorldQA | test | Acc. | 765 | 51.9 | 61.4 | 67.5 | - | 63.1 | 65.4 | 60.0 | 61.0 | - |
| LLaVA-W** | test | GPT4-Eval | 60 | - | 98.0 | - | 82.3 | 90.4 | 89.2 | 80.1 | 88.8 | 59.6 |
| LLaVA-Bench (Wilder) | Small | GPT4V-Eval | 120 | 68.6 | 71.5 | 70.5 | - | 70.5 | 71.2 | 62.5 | - | |
| Medium | GPT4V-Eval | 1020 | 79.7 | 78.5 | - | - | 72.5 | 73.4 | 63.1 | - | - | |
| *Train split observed during SFT stage. | ||||||||||||
| **We report the evaluation results with GPT-4-0613 on LLaVA-W. | ||||||||||||
[Fold / Unfold to see qualitative examples]

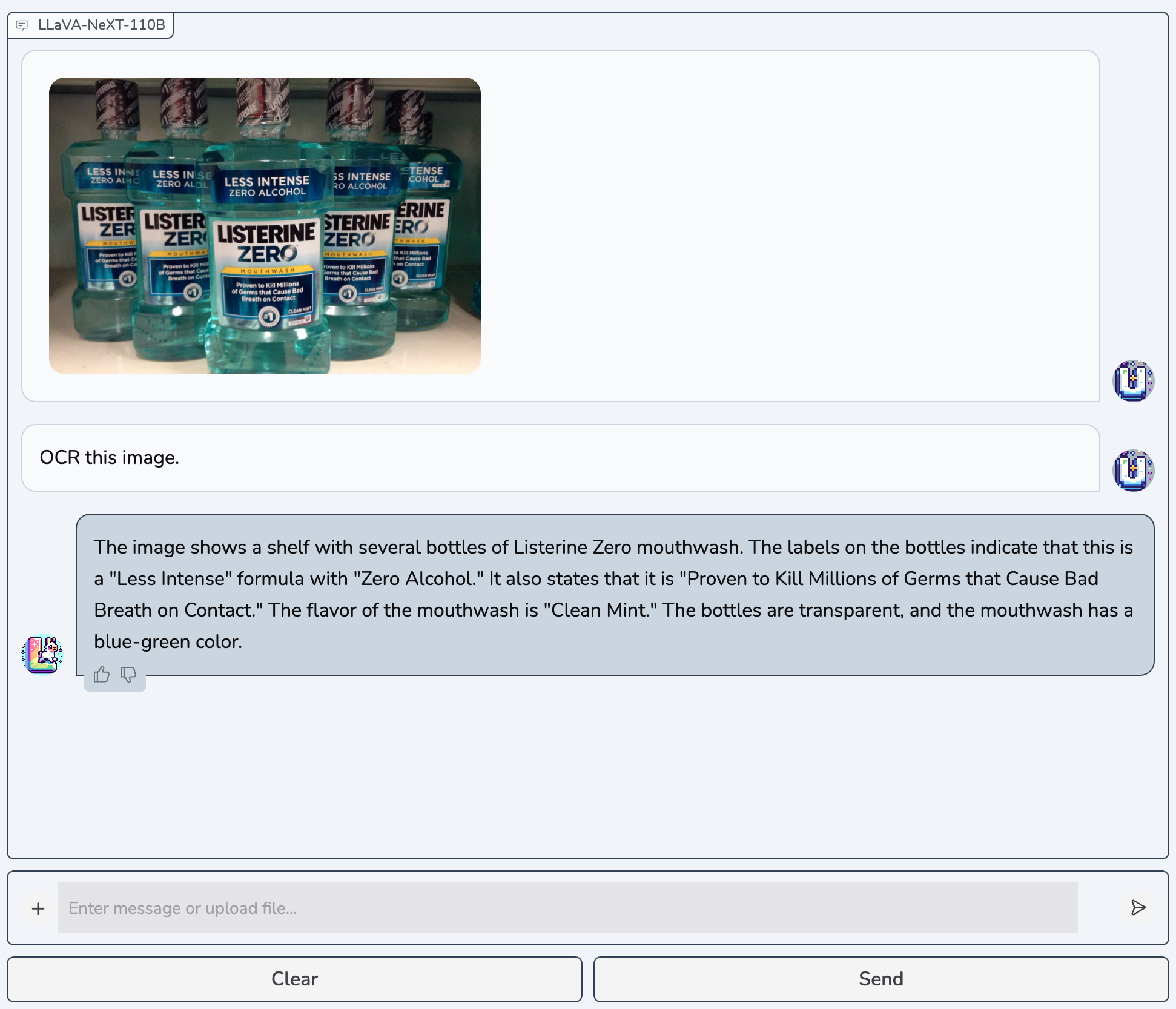
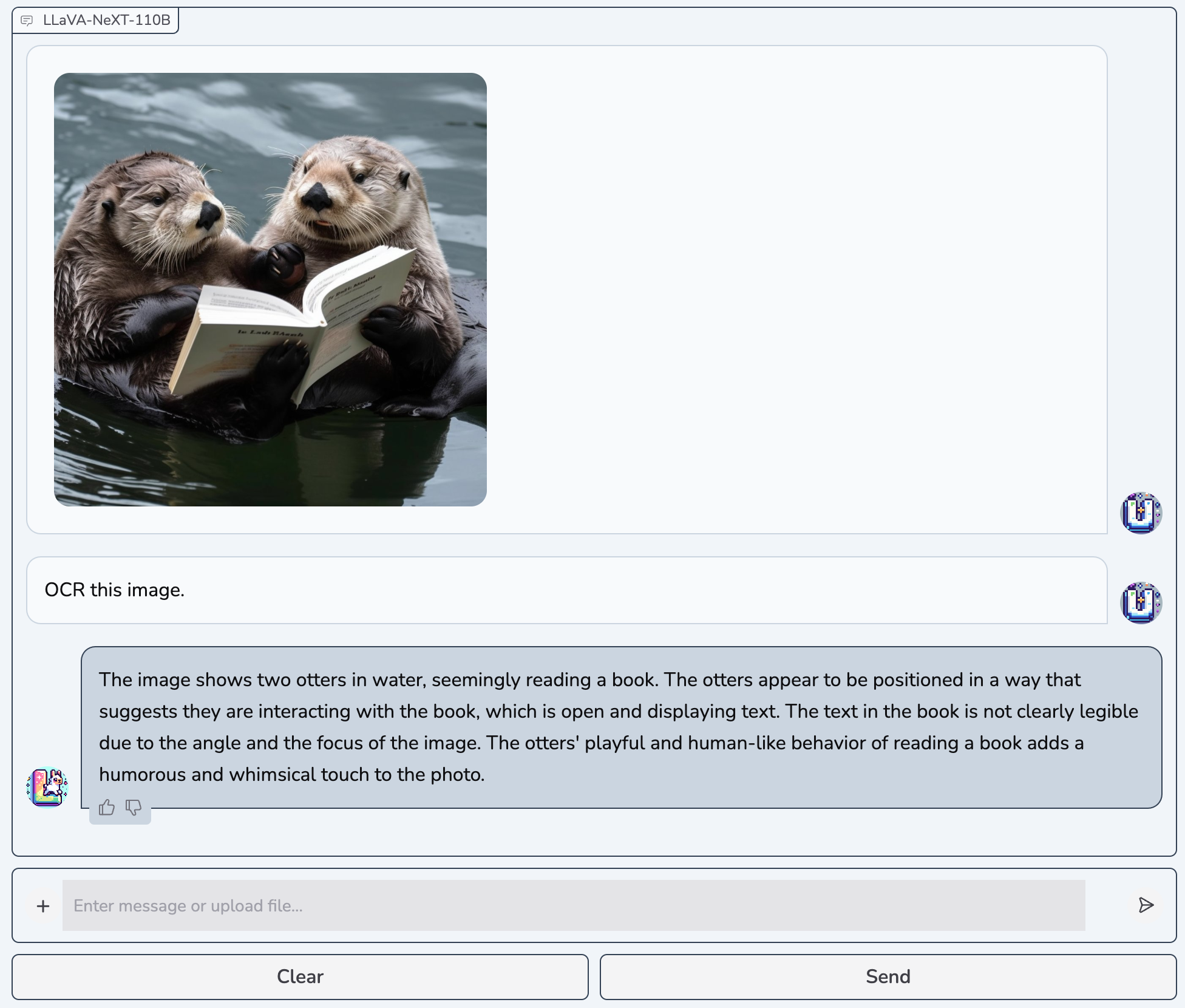
Exploring the Capability Limit of Large Language Models
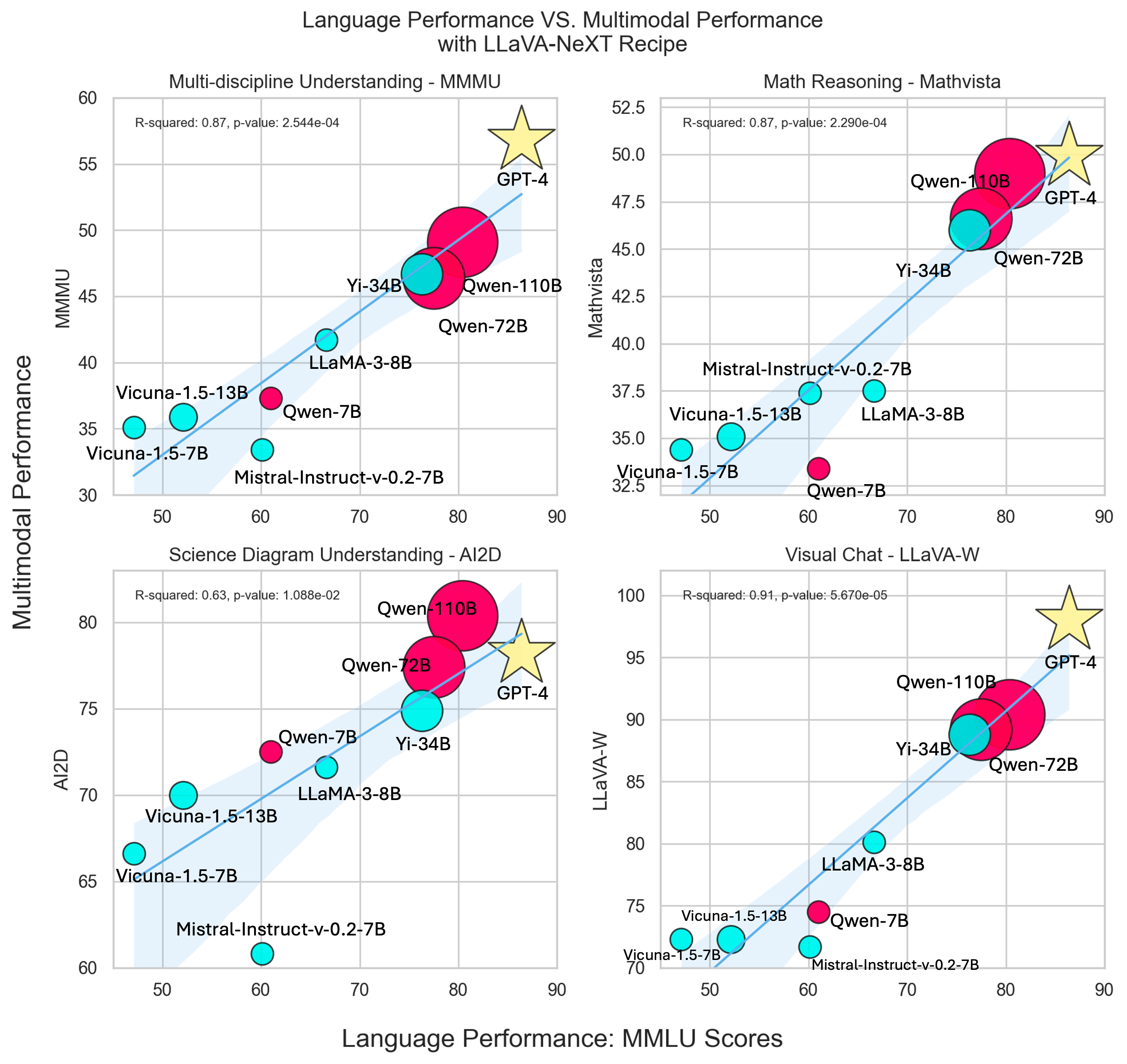
In our exploration with LLaVA-NeXT, we witnessed a significant performance leap when scaling LLM from 13B to 34B. With the emergence of more powerful open LLMs, there arises a natural curiosity to push the boundaries of multimodal performance, prompting the question: How effectively can the language capabilities of LLMs be transferred to multimodal settings? To measure the language capability of LLMs, we employ evaluation scores from the Massive Multitask Language Understanding (MMLU) benchmark. To measure the multimodal capability after applying the same LLaVA-NeXT training recipe, we examine four key benchmarks: MMMU for multidisciplinary understanding, Mathvista for visual math reasoning, AI2D for science diagram comprehension, and LLaVA-W for daily visual chat scenarios. These benchmarks encapsulate diverse real-world applications of LMM in the wild.The correlation between multimodal and language capabilities is visually depicted in Figure 1, utilizing regression lines to illustrate trends across each benchmark.
- Improved Language Capability: Across LLMs of comparable sizes (e.g., 7B Mistral/Vicuna, 7B Qwen, 8B LLaMa3), there exists a consistent pattern where higher language proficiency, as measured by MMMU scores, corresponds to improved multimodal capabilities.
- Influence of Model Size: Within the same LLM family (e.g., Qwen LLM: 7B, 72B, 110B), larger models consistently demonstrate superior performance on multimodal benchmarks. This underscores the notion that larger models tend to possess enhanced language capabilities, leading to improved performance across multimodal tasks.
[Fold / Unfold to see the table for details]
| Models | Language Performance | Multimodal Performance | |||
|---|---|---|---|---|---|
| - | MMLU | MMMU | MathVista | AI2D | LLaVA-W |
| GPT4-V | 86.4 | 56.8 | 49.9 | 78.2 | 98.0 |
| Qwen1.5 (110B) | 80.4 | 49.1 | 49.0 | 80.4 | 90.4 |
| Qwen1.5 (72B) | 77.5 | 46.4 | 46.6 | 77.4 | 89.2 |
| Yi (34B) | 76.3 | 46.7 | 46.0 | 74.9 | 88.8 |
| Llama 3 (8B) | 66.6 | 41.7 | 37.5 | 71.6 | 80.1 |
| Qwen1.5 (7B) | 61.0 | 37.3 | 33.5 | 72.5 | 74.5 |
| Mistral-Instruct-v0.2 (7B) | 60.1 | 33.4 | 37.4 | 60.8 | 71.7 |
| Vicuna1.5 (13B) | 52.1 | 35.9 | 35.1 | 70.0 | 72.3 |
| Vicuna1.5 (7B) | 47.1 | 35.1 | 34.4 | 66.6 | 72.3 |
LLaVA-Bench (Wilder): Daily-life Visual Chat Benchmarks
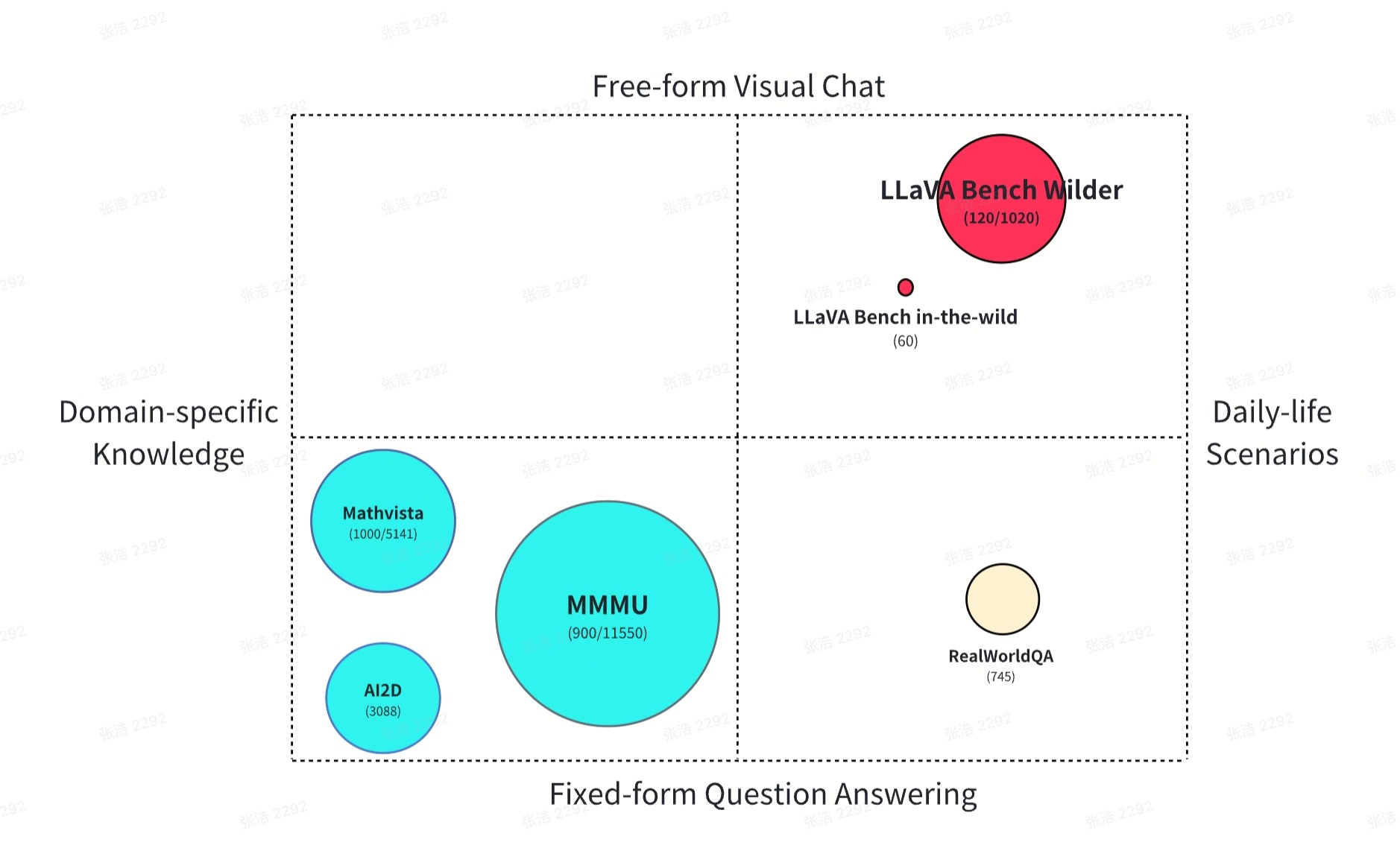
One of the ultimate goals to develop LLMs is to build general-purpose assistant of aiding humans in various multimodal tasks in their daily lives. It is thus important to have robust benchmarks to precisely measure the related progresses. LLaVA-Bench (In-the-Wild), also known as LLaVA-W, is such a benchmark to measure the daily-life visual chat capability of LMMs. However, with only 60 examples available, we recognized the need for a more expansive dataset. In line with this spirit, we introduce LLaVA-Bench (Wilder), comprising two versions: a smaller iteration featuring 120 examples for swift assessment, and a medium-sized version with 1020 examples for comprehensive measurement. These datasets encompass diverse scenarios such as mathematical problem-solving, image comprehension, code generation, visual AI assistance, and image-based reasoning. To construct these datasets, we gathered instructions and images reflecting real-world user requests from an online service. Subsequently, we meticulously filtered samples to address privacy concerns and mitigate potential harm. Responses to these prompts were generated using GPT4-V.Comparison with other benchmarks. Figure 2 provides a visual comparison between LLaVA-Bench (Wider) and existing LMM evaluation benchmarks. Many current benchmarks adopt a fixed-form question-and-answer (QA) format, chosen for its ease of use in evaluating metrics and presenting model comparisons. Reflecting this trend, benchmarks like MMMU, Mathvista, and AI2D are tailored to assess LMM performance in specific knowledge-intensive domains. In contrast, RealWorldQA focuses on everyday scenarios but is confined to short-answer formats. However, as assistant models, possessing the ability to engage users in free-form conversations is crucial for eliciting interest, surpassing the limitations of simple short-answer interactions. Hence, the inclusion of free-form conversation in daily-life visual chat scenarios becomes pivotal. LLaVA-W sets the precedent by introducing such a benchmark prototype, and LLaVA-Bench-Wilder endeavors to build upon this benchmark by including more daily-life scenarios and covering different applications.
[Fold / Unfold to see the table for details]
| Benchmarks | Instances | Multimodal Capabilities | Instruction Format | Response Format | Evaluation Metric |
|---|---|---|---|---|---|
| AI2D | 3088 | Science Diagrams Understanding | Multiple Choices | Options | Exact Match |
| MMMU | 900 | Multi-dimensional Understanding & Reasoning | Multiple Choices, Short Responses | Options & Short Responses | Exact Match |
| MathVista | 1000 | Math Reasoning | Multiple Choices, Short Responses | Options & Short Responses | GPT-4 Extract & Exact Match |
| RealWorldQA | 765 | Real-world Visual Question Answering | Multiple Choices, Short Responses | Options & Short Responses | Filtered Match |
| LLaVA-Bench (in-the-Wild) | 60 | Real-life Visual Chat | Free-form | Free-form | GPT-4 Evaluation |
| LLaVA-Bench (Wilder) | Small: 120 | Real-life Visual Chat | Free-form | Free-form | GPT4-V Evaluation |
| LLaVA-Bench (Wilder) | Medium: 1020 | Real-life Visual Chat | Free-form | Free-form | GPT4-V Evaluation |
Construction & Evaluation Metrics. For a larget set of queries from the online services, we used the ONE-PEACE embedding model to generate embeddings. Next, we applied weighted K-Means clustering, using the min-max normalized total pixel values of the image as weights, ensuring images with higher pixel values were more likely to be included in our test set. After removing duplicates, we ended up with a small version containing 120 questions and a medium version containing 1020 questions. We also conducted decontamination checks to ensure the dataset is clean and not contaminated. Both versions have less than 2% image overlap. For comparison, the original LLaVA-W had 5% image overlap. The evaluation data is excluded and decontainminated from LLaVA-NeXT's training data.
Reference Answer Construction. For each screened question, we first used GPT4V to generate a reference response and involved human annotators to manually verify the accuracy of both the question and the reference answer. A considerable number of users' inquiries were vague, involving queries about image resolution, grammar errors, or being unrelated to uploaded images. In these cases, GPT4V may decline to respond, or the reference answers provided could be incorrect. To maintain the evaluation data's quality, we manually reviewed and revised problematic answers, ensuring accuracy and reliability.
Scoring Methodology. We adopted the same evaluation process as LLaVA-W, but we substituted GPT-4 with GPT4-V. Instead of using multiple categories as in LLaVA-W, we simply calculated the overall score ratio between the GPT4-V reference answer and the model's response. In our evaluation, we noticed that the score doesn't show the problems well in different models and might unfairly lower the scores of the reference answers, resulting the bad cases of model can not be correctly reflected in the overall score. To fix this, we made GPT4-V always think the right answers are perfect and give them a score of ten. This means the other models get lower scores and get punished more for their mistakes. This helps us to evaluate abilities of the model better for real-life situations.
Comparison of Benchmarks & Models
Quantative Results. The distinctive measurement provided by LLaVA-Bench (Wilder) compared to other benchmarks becomes evident due to the substantial performance gap among state-of-the-art (SoTA) LMMs. Certain highly proficient LMMs in knowledge-intensive tasks may not excel in daily-life visual chat scenarios as assessed by LLaVA-Bench (Wilder). The LLaVA-NeXT models featured in this release persist in advancing performance across various domains.| Models | LLaVA-Bench Wilder (Small | Medium) | LLaVA-W | RealWorldQA | AI2D | MME | MMMU | MathVista | |
|---|---|---|---|---|---|---|---|---|
| LLaVA-NeXT in this release | ||||||||
| LLaVA-Next-110B | 70.5 | 72.5 | 90.4 | 63.2 | 80.4 | 2200.4 | 49.1 | 49.0 |
| LLaVA-Next-72B | 71.2 | 73.4 | 89.2 | 65.4 | 77.4 | 2158.9 | 46.4 | 46.6 |
| LLaMA3-LLaVA-Next-8B | 62.5 | 63.1 | 80.1 | 60.0 | 71.6 | 1971.5 | 41.7 | 37.5 |
| Previous Open-sourced State-of-the-Art Models | ||||||||
| LLaVA-Next-34B | - | - | 88.8 | 61.7 | 74.9 | 2030.4 | 46.7 | 46.5 |
| Intern-VL-1.5 | 62.4 | - | 83.3 | 66.0 | 80.7 | 2187.8 | 46.8 | 54.7 |
| Commercial State-of-the-Art Models | ||||||||
| Qwen-VL-Max | - | - | - | - | 79.3 | 2281.7 | 51.4 | 51.0 |
| GPT4-V | 71.5 | 78.5 | 98.0 | 61.4 | 78.2 | 1926.0 | 56.8 | 49.9 |
| Claude-3-Opus | 68.6 | 79.7 | 98.5 | 49.8 | 88.1 | 59.4 | 50.5 | - |
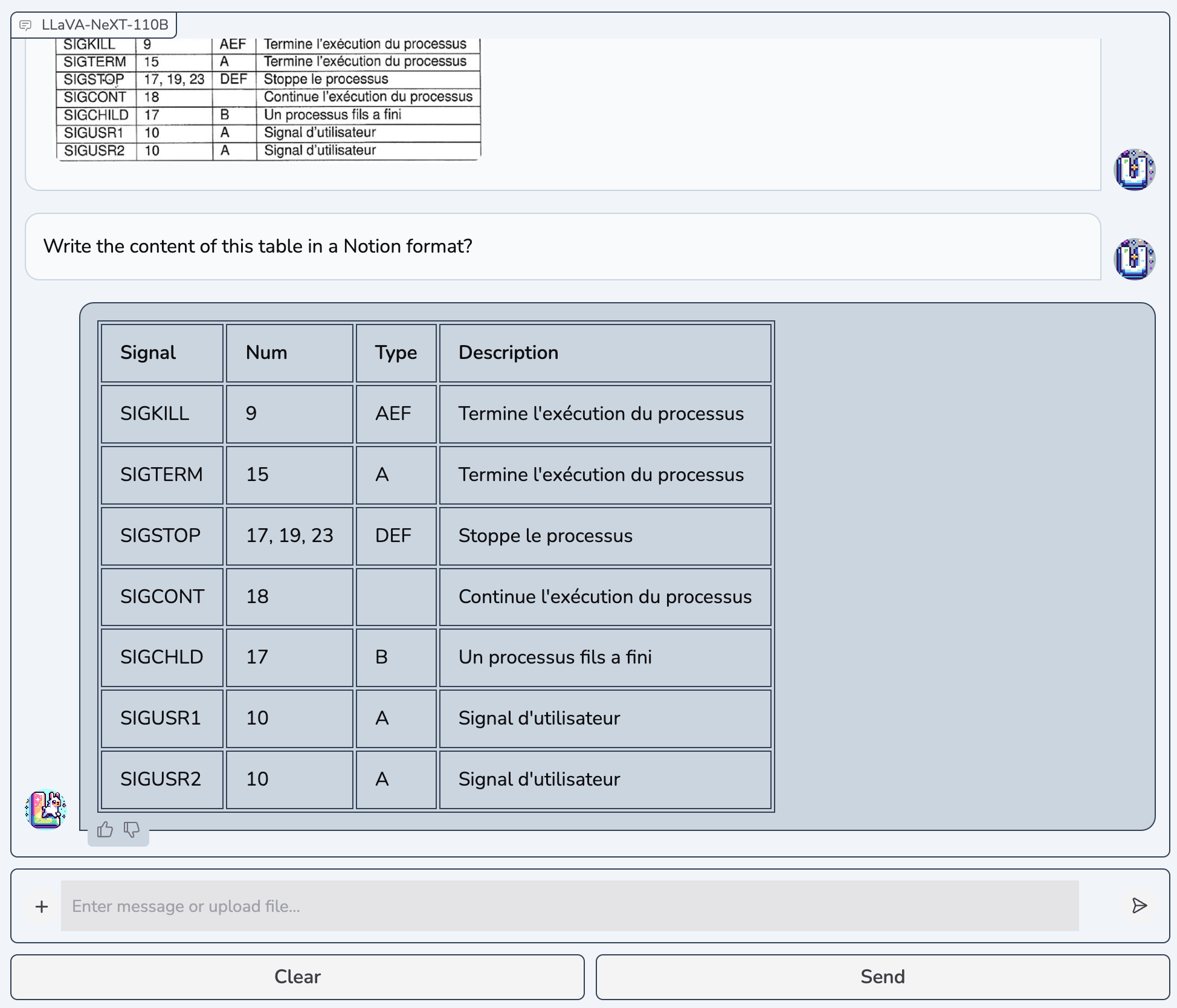
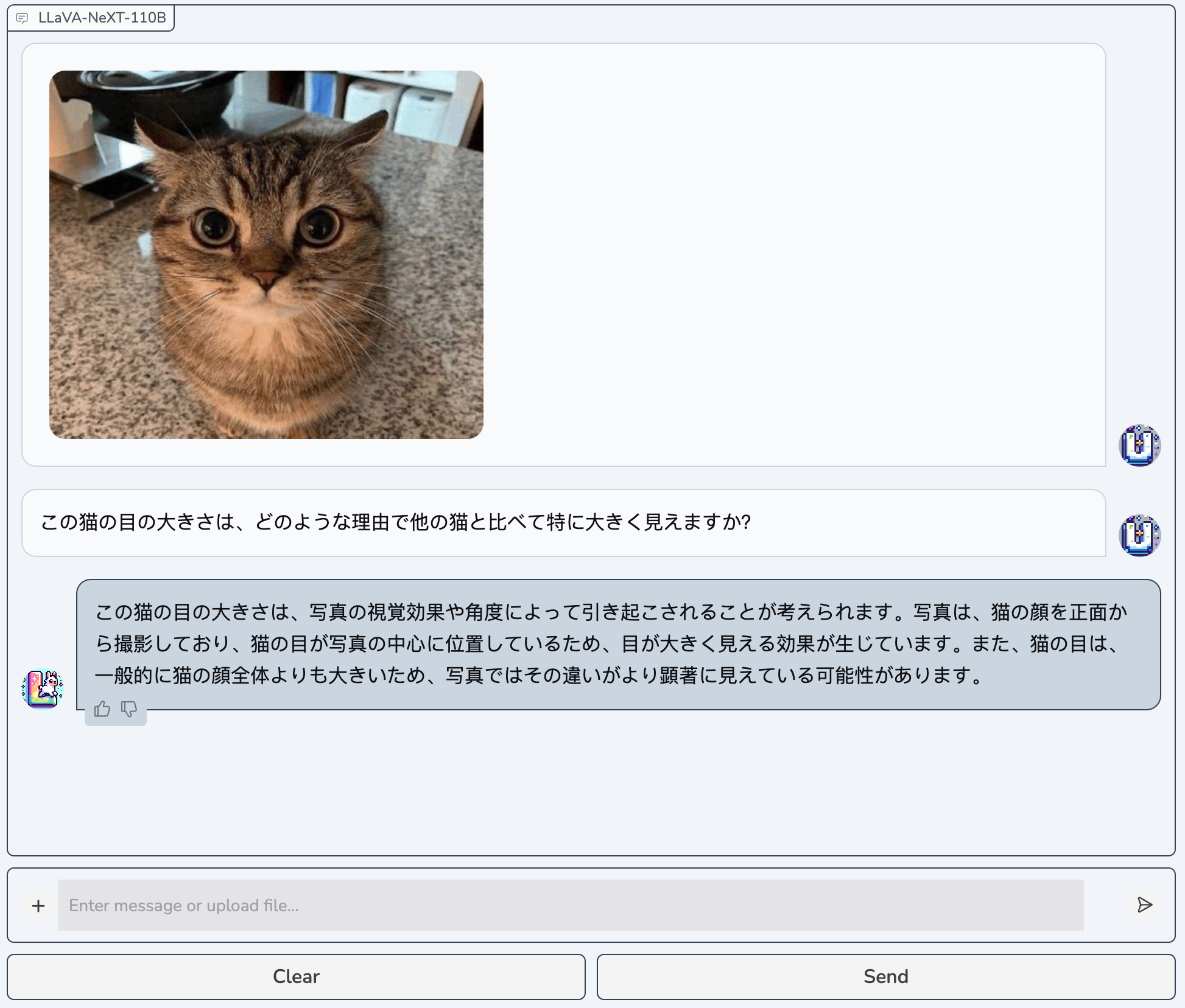
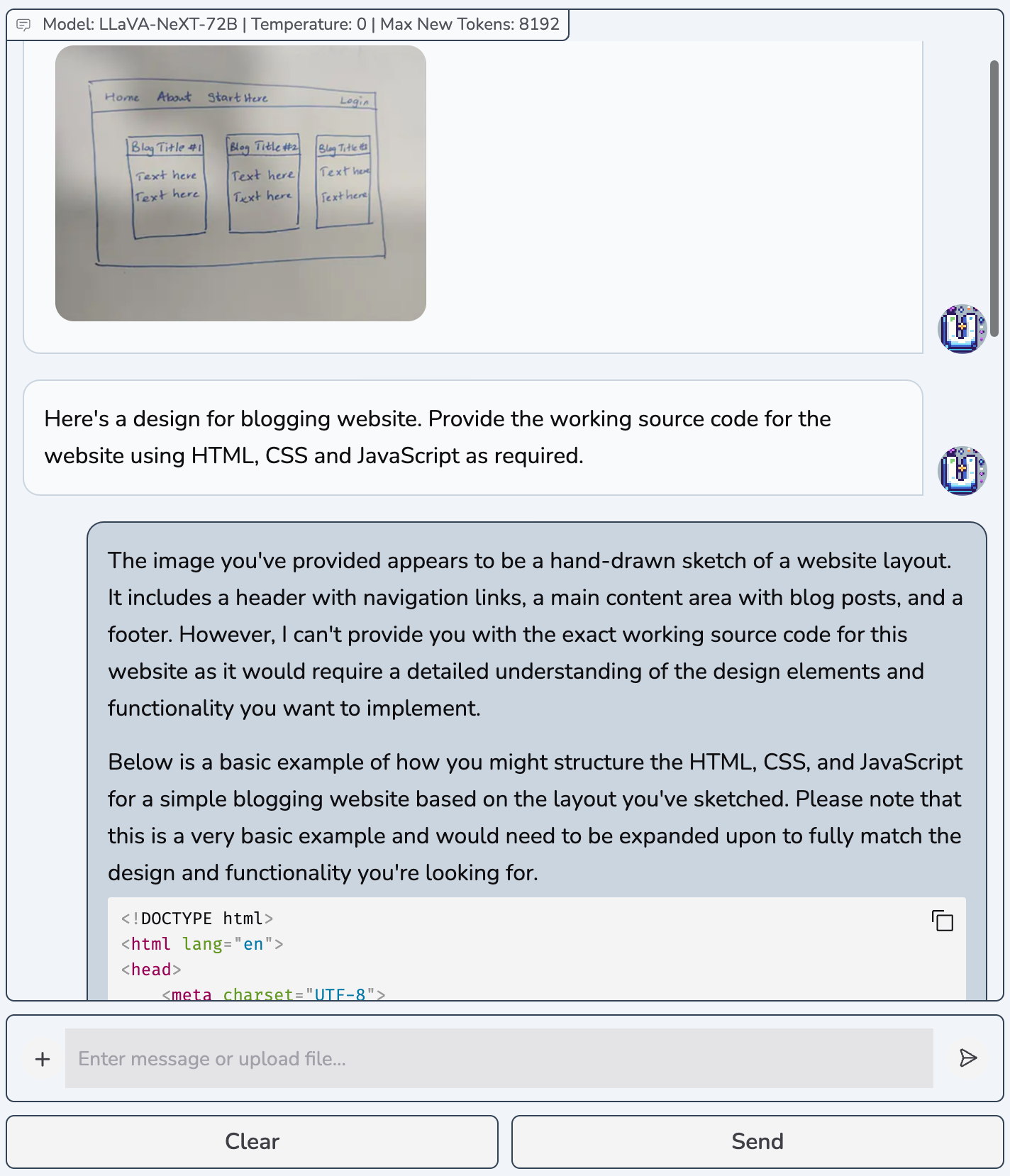
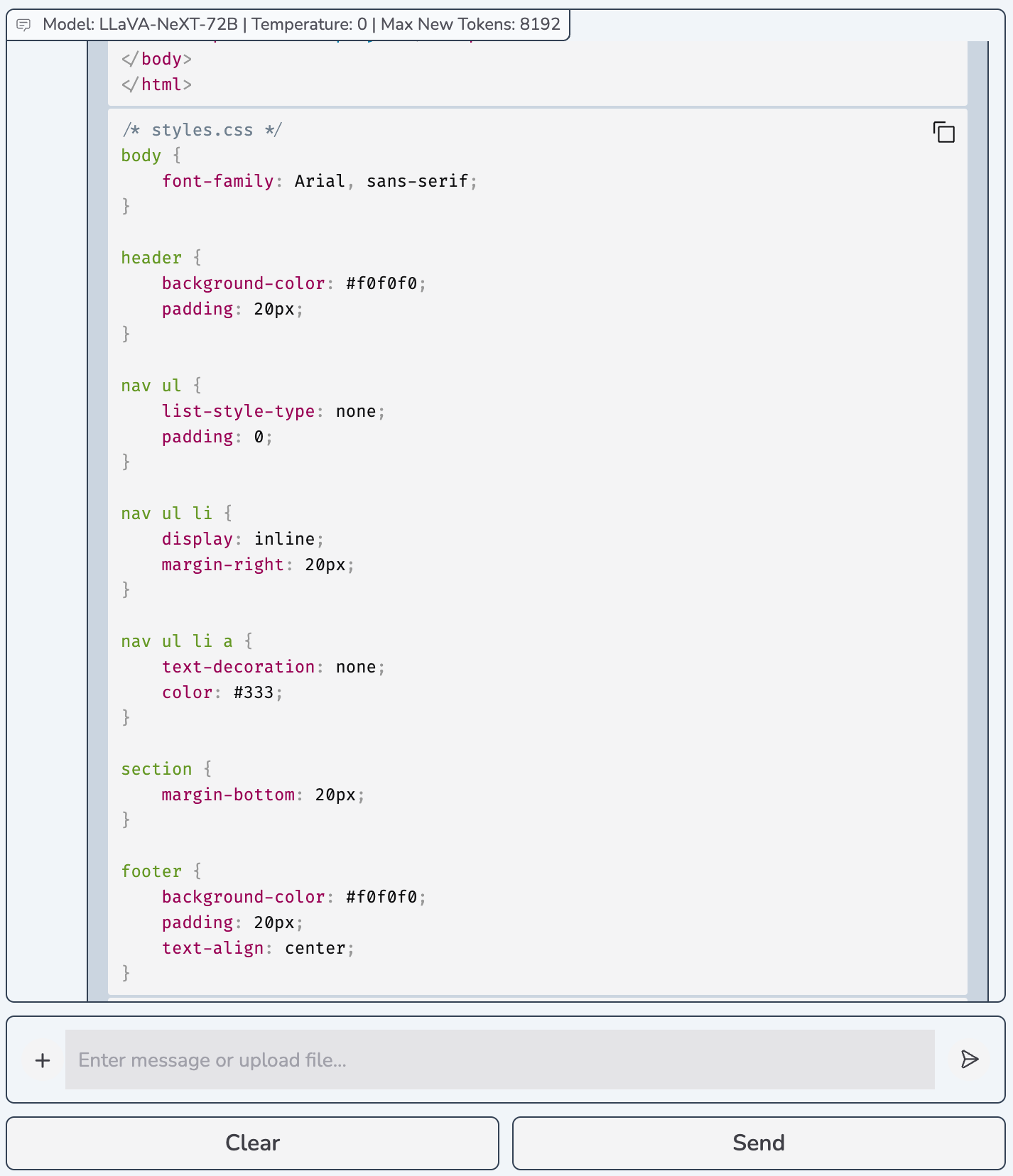
Daily-life Scenarios & Qualitative Comparisons

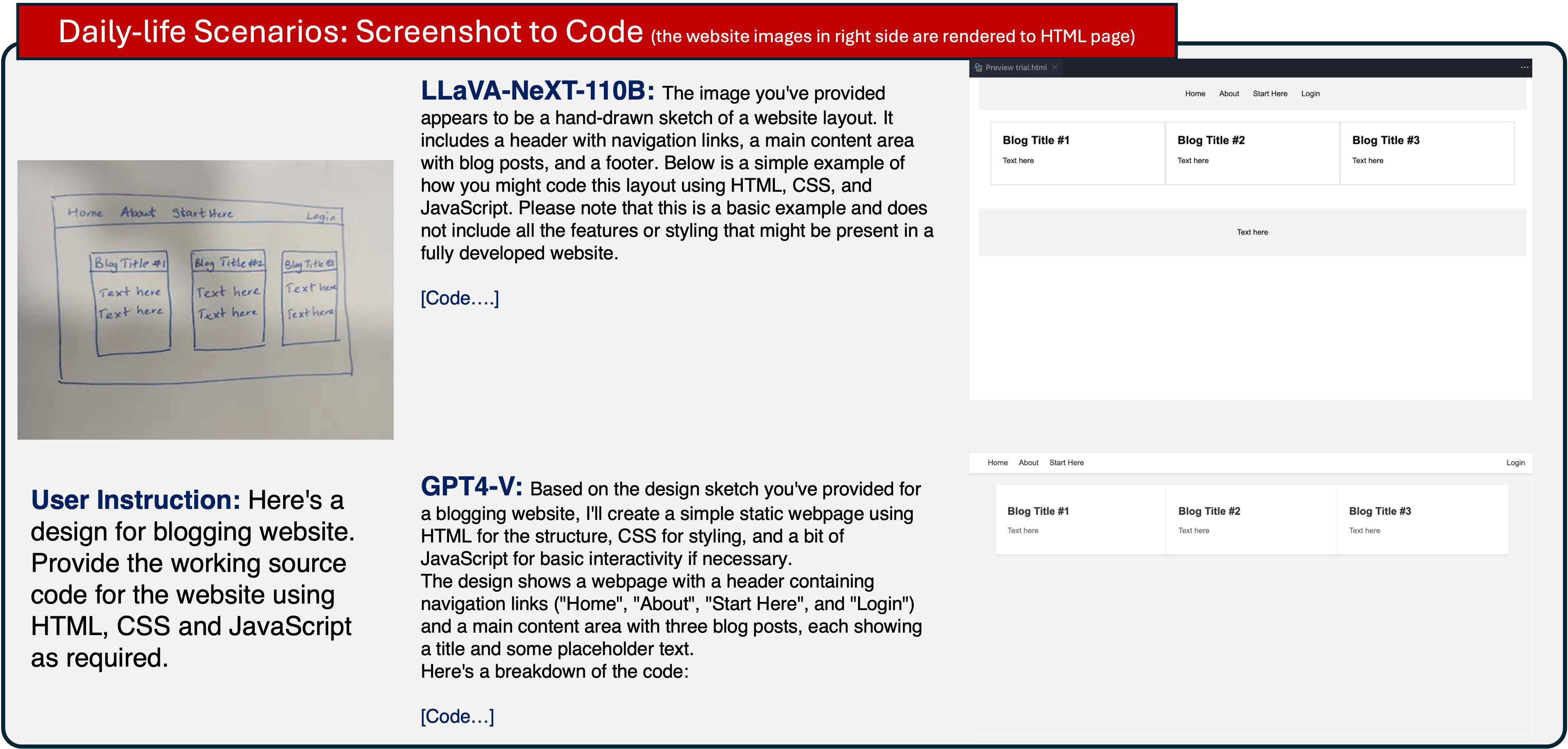



The detailed model outputs for HTML code scenario are available here.
Model Card
| Name | LLaMA-3-LLaVA-NeXT-8B | LLaVA-NeXT-72B | LLaVA-NeXT-110B | |
|---|---|---|---|---|
| Model Size | Total | 8.35B | 72.7B | 111.5B |
| Vision Encoder | 303.5M | 303.5M | 303.5M | |
| Connector | 20.0M | 72.0M | 72.0M | |
| LLM | 8.03B | 72.3B | 111.0B | |
| Resolution | 336 x [(2,2), (1,2), (2,1), (1,3), (3,1)] | |||
| Stage-1 | Training Data | 558K | ||
| Trainable Module | Connector | |||
| Stage-2 | Training Data | ~790K | ||
| Trainable Module | Full model | |||
| Compute (#GPU x #Hours) | 16 A100-80G x 15~20 hours | 128 A100-80G x ~18 hours | 128 H800-80G x ~18 hours | |
| Total Training Data (#Samples) | 1348K | |||
Team
- Bo Li: Nanyang Technological University
 (Work collaborated with ByteDance/TikTok)
(Work collaborated with ByteDance/TikTok) - Kaichen Zhang: Nanyang Technological University (Work collaborated with ByteDance/TikTok)
- Hao Zhang: Hong Kong University of Science and Technology
 (Work collaborated with ByteDance/TikTok)
(Work collaborated with ByteDance/TikTok) - Dong Guo: ByteDance/Tiktok

- Renrui Zhang: The Chinese University of Hong Kong
 (Work collaborated with ByteDance/TikTok)
(Work collaborated with ByteDance/TikTok) - Feng Li: Hong Kong University of Science and Technology (Work collaborated with ByteDance/TikTok)
- Yuanhan Zhang: Nanyang Technological University (Work collaborated with ByteDance/TikTok)
- Ziwei Liu: Nanyang Technological University
- Chunyuan Li: Bytedance/Tiktok
Acknowledgement
- We thank Fanyi Pu, Shuai Liu, Kairui Hu for the continuous contribution of lmms-eval to accelerate our development of LLaVA-NeXT.
Related Blogs
- LLaVA-NeXT: A Strong Zero-shot Video Understanding Model
- LLaVA-NeXT: Improved reasoning, OCR, and world knowledge
- Accelerating the Development of Large Multimodal Models with LMMs-Eval
Citation
@misc{li2024llavanext-strong,
title={LLaVA-NeXT: Stronger LLMs Supercharge Multimodal Capabilities in the Wild},
url={https://llava-vl.github.io/blog/2024-05-10-llava-next-stronger-llms/},
author={Li, Bo and Zhang, Kaichen and Zhang, Hao and Guo, Dong and Zhang, Renrui and Li, Feng and Zhang, Yuanhan and Liu, Ziwei and Li, Chunyuan},
month={May},
year={2024}
}
@misc{liu2024llavanext,
title={LLaVA-NeXT: Improved reasoning, OCR, and world knowledge},
url={https://llava-vl.github.io/blog/2024-01-30-llava-next/},
author={Liu, Haotian and Li, Chunyuan and Li, Yuheng and Li, Bo and Zhang, Yuanhan and Shen, Sheng and Lee, Yong Jae},
month={January},
year={2024}
}
@misc{liu2023improvedllava,
title={Improved Baselines with Visual Instruction Tuning},
author={Liu, Haotian and Li, Chunyuan and Li, Yuheng and Lee, Yong Jae},
publisher={arXiv:2310.03744},
year={2023},
}
@misc{liu2023llava,
title={Visual Instruction Tuning},
author={Liu, Haotian and Li, Chunyuan and Wu, Qingyang and Lee, Yong Jae},
publisher={NeurIPS},
year={2023},
}