LLaVA-NeXT: Improved reasoning, OCR, and world knowledge
In October 2023, we released LLaVA-1.5 with a simple and efficient design along with great performance on a benchmark suite of 12 datasets. It has since served as the foundation of many comprehensive studies of data, model, and capabilities of large multimodal models (LMM), and has enabled various new applications.
Today, we are thrilled to present LLaVA-NeXT, with improved reasoning, OCR, and world knowledge. LLaVA-NeXT even exceeds Gemini Pro on several benchmarks.
Compared with LLaVA-1.5, LLaVA-NeXT has several improvements:
- Increasing the input image resolution to 4x more pixels. This allows it to grasp more visual details. It supports three aspect ratios, up to 672x672, 336x1344, 1344x336 resolution.
- Better visual reasoning and OCR capability with an improved visual instruction tuning data mixture.
- Better visual conversation for more scenarios, covering different applications. Better world knowledge and logical reasoning.
- Efficient deployment and inference with SGLang.
Along with performance improvements, LLaVA-NeXT maintains the minimalist design and data efficiency of LLaVA-1.5. It re-uses the pretrained connector of LLaVA-1.5, and still uses less than 1M visual instruction tuning samples. The largest 34B variant finishes training in ~1 day with 32 A100s. Code, data, model will be made publicly available.
Open-Source Release
We open-source the LLaVA-NeXT to facilitate future development of LMM in the community. Code, data, model will be made publicly available.
Results
| Data (PT) | Data (IT) | Model | MMMU (val) | Math-Vista | MMB-ENG | MMB-CN | MM-Vet | LLaVA-Wild | SEED-IMG |
|---|---|---|---|---|---|---|---|---|---|
| N/A | N/A | GPT-4V | 56.8 | 49.9 | 75.8 | 73.9 | 67.6 | - | 71.6 |
| N/A | N/A | Gemini Ultra | 59.4 | 53 | - | - | - | - | - |
| N/A | N/A | Gemini Pro | 47.9 | 45.2 | 73.6 | 74.3 | 64.3 | - | 70.7 |
| 1.4B | 50M | Qwen-VL-Plus | 45.2 | 43.3 | - | - | 55.7 | - | 65.7 |
| 1.5B | 5.12M | CogVLM-30B | 32.1 | - | - | - | 56.8 | - | - |
| 125M | ~1M | Yi-VL-34B | 45.9 | - | - | - | - | - | - |
| 558K | 665K | LLaVA-1.5-13B | 36.4 | 27.6 | 67.8 | 63.3 | 36.3 | 72.5 | 68.2 |
| 558K | 760K | LLaVA-NeXT-34B | 51.1 | 46.5 | 79.3 | 79 | 57.4 | 89.6 | 75.9 |
For more results, please unfold to see expanded tables
More benchmarks will be added soon.| Model | VQAv2 | GQA | VisWiz | TextVQA | ScienceQA |
|---|---|---|---|---|---|
| GPT-4V | 77.2 | - | - | 78.0 | - |
| Gemini Ultra | 77.8 | - | - | 82.3 | - |
| Gemini Pro | 71.2 | - | - | 74.6 | - |
| PALI-X | 86.0$^\dagger$ | - | 70.9$^\dagger$ | 71.4$^\dagger$ | - |
| CogVLM-30B | 83.4 (84.7$^\dagger$) | 65.2$^\dagger$ | 76.4$^\dagger$ | 68.1 (69.3$^\dagger$) | 92.7$^\dagger$ |
| LLaVA-1.5-13B | 80 | 63.3 | 53.6 | 61.3$^*$ | 71.6 |
| LLaVA-NeXT-Vicuna-7B | 81.8 | 64.2 | 57.6 | 64.9 | 70.1 |
| LLaVA-NeXT-Vicuna-13B | 82.8 | 65.4 | 60.5 | 67.1 | 73.6 |
| LLaVA-NeXT-Mistral-7B | 82.2 | 64.8 | 60.0 | 65.7 | 72.8 |
| LLaVA-NeXT-34B | 83.7 | 67.1 | 63.8 | 69.5 | 81.8 |
| Data (PT) | Data (IT) | Model | MMMU (val) | MMMU (test) | MathVista | MMB-ENG | MMB-CN | MM-Vet | LLaVA-Wild | SEED-IMG | MME | POPE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| N/A | N/A | GPT-4V | 56.8 | 55.7 | 49.9 | 75.8 | 73.9 | 67.6 | - | 71.6 | - | - |
| N/A | N/A | Gemini Ultra | 59.4 | - | 53 | - | - | - | - | - | - | - |
| N/A | N/A | Gemini Pro | 47.9 | - | 45.2 | 73.6 | 74.3 | 64.3 | - | 70.7 | - | - |
| 1.4B | 50M | Qwen-VL-Plus | 45.2 | 40.8 | 43.3 | - | - | - | - | - | - | - |
| 1.5B | 5.12M | CogVLM-30B | 32.1 | 30.1 | - | - | - | 56.8 | - | - | - | - |
| 558K | 665K | LLaVA-1.5-13B (336$^2$) | 36.4 | 33.6 | 27.6 | 67.8 | 63.3 | 36.3 | 72.5 | 68.2 | 1531/295 | 85.93 |
| 558K | 760K | LLaVA-NeXT-Vicuna-7B (672$^2$) | 35.8 | - | 34.6 | 67.4 | 60.6 | 43.9 | 81.6 | 70.2 | 1519/332 | 86.53 |
| 558K | 760K | LLaVA-NeXT-Mistral-7B (672$^2$) | 35.3 | - | 37.7 | 68.7 | 61.2 | 47.3 | 83.2 | 72.2 | 1498/321 | 86.73 |
| 558K | 760K | LLaVA-NeXT-13B (672$^2$) | 36.2 | - | 35.3 | 70 | 64.4 | 48.4 | 87.3 | 71.9 | 1575/326 | 86.23 |
| 558K | 760K | LLaVA-NeXT-34B (672$^2$) | 51.1 | 44.7 | 46.5 | 79.3 | 79 | 57.4 | 89.6 | 75.9 | 1631/397 | 87.73 |
✨ Highlights:
- SoTA Performance! LLaVA-NeXT achieves the best performance compared with open-source LMMs such as CogVLM or Yi-VL. Compared with commercial ones, it catches up to Gemini Pro and outperforms Qwen-VL-Plus on selected benchmarks.
- Zero-shot Chinese capability. LLaVA-NeXT’s Chinese capability is an emerging zero-shot capability (i.e., only English multimodal data is considered). Its performance on Chinese multimodal scenarios is surprisingly good, e.g., SoTA on MMBench-CN.
- Low Training Cost. LLaVA-NeXT is trained with 32 GPUs for ~1 day, with 1.3M data samples in total. The compute / training data cost is 100-1000 times smaller than others.
Qualitative Results
Mark Zuckerberg talks about Llama-3 and 600K H100s
User: Explain this to me in detail.
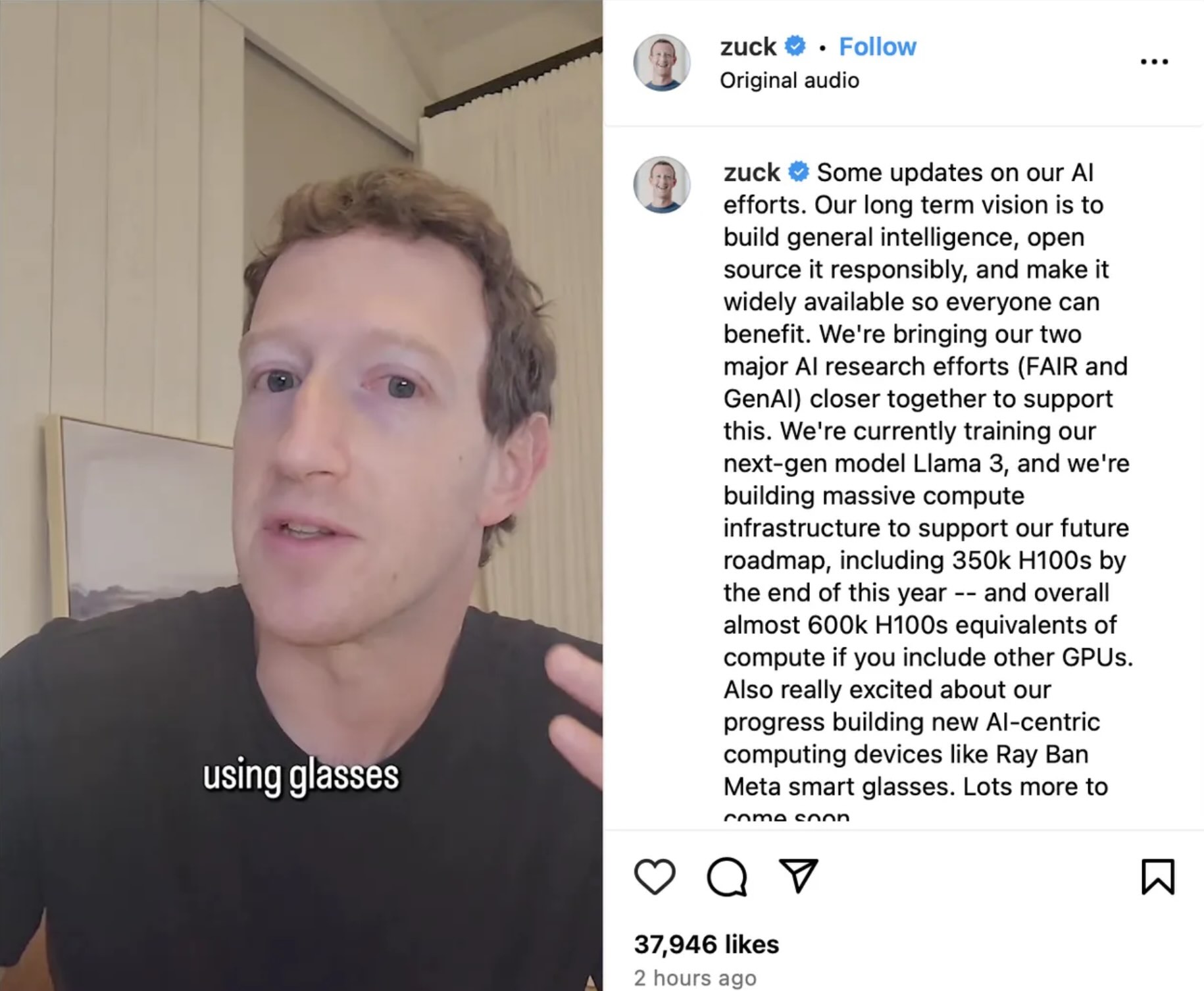
LLaVA-NeXT-34B
The image you've provided appears to be a screenshot of a social media post, specifically from Instagram, featuring a man speaking and a text overlay. The man in the image is wearing a black t-shirt and appears to be in the middle of a conversation or presentation. The text overlay is a quote from a post by a user named "zuck," which is presumably a reference to Mark Zuckerberg, the CEO of Meta (formerly known as Facebook).
The text overlay reads:
"Some updates on our AI efforts. Our long term vision is to build general intelligence, open source it responsibly, and make it widely available so everyone can benefit. We're bringing our two major AI research efforts (FAIR and GenAI) closer together to support this. We're currently training our next-gen model Llama 3, and we're building massive compute infrastructure to support our future roadmap, including 35k H100s by the end of this year — and overall almost 600k H100s equivalents of compute if you include other GPUs. Also really excited about our progress building new AI-centric computing devices like Ray Ban Meta smart glasses. Lots more to come."
This text provides insights into Meta's artificial intelligence (AI) initiatives. It mentions that the company's long-term goal is to develop general intelligence and make it accessible to everyone. The post also discusses the integration of Meta's two AI research efforts, FAIR (Facebook AI Research) and GenAI, to support this goal.
The text also mentions the training of a next-generation AI model called Llama 3 and the construction of massive compute infrastructure to support Meta's future plans. It highlights the company's investment in NVIDIA's H100 GPUs, with a total of 35,000 H100s by the end of the year and almost 600,000 H100s equivalents of compute if other GPUs are included.
Lastly, the post expresses excitement about Meta's progress in developing AI-centric computing devices, specifically Ray Ban Meta smart glasses. The post concludes with a statement that there is more to come, suggesting that Meta has additional AI-related announcements or developments in the pipeline.
The image of the man speaking could be from a video or a live stream where he is discussing these AI updates. The context of the image suggests that it is part of a larger conversation or announcement related to Meta's AI strategy and advancements.
When to leave to pickup based on flight info?
User: I need to pick up my wife. I live in San Jose. When should I leave?

LLaVA-NeXT-34B
Based on the information provided in the image, the flight is scheduled to arrive at 11:51 AM at San Francisco International Airport (SFO). If you live in San Jose, you should consider the travel time between San Jose and San Francisco, which is approximately 45-60 minutes depending on traffic conditions.
To ensure you have enough time to pick up your wife, you should leave San Jose no later than 11:00 AM to account for traffic and any unexpected delays. However, it's always a good idea to leave earlier than necessary to ensure you arrive on time.
Detailed Technical Improvement
We detail the findings we have and improvements we make to LLaVA-1.5. More implementation details will be released and documented here in the coming days.
(1) Dynamic High Resolution
We design our model at high resolution with an aim to preserve its data efficiency. When provided with high-resolution images and representations that preserve these details, the model’s capacity to perceive intricate details in an image is significantly improved. It reduces the model hallucination that conjectures the imagined visual content when confronted with low-resolution images. Our ‘AnyRes’ technique is designed to accommodate images of various high resolutions. We employ a grid configuration of $\{2 \times 2, 1 \times \{2,3,4\}, \{2,3,4\} \times 1\}$, balancing performance efficiency with operational costs. See our updated LLaVA-1.5 technical report for more details.
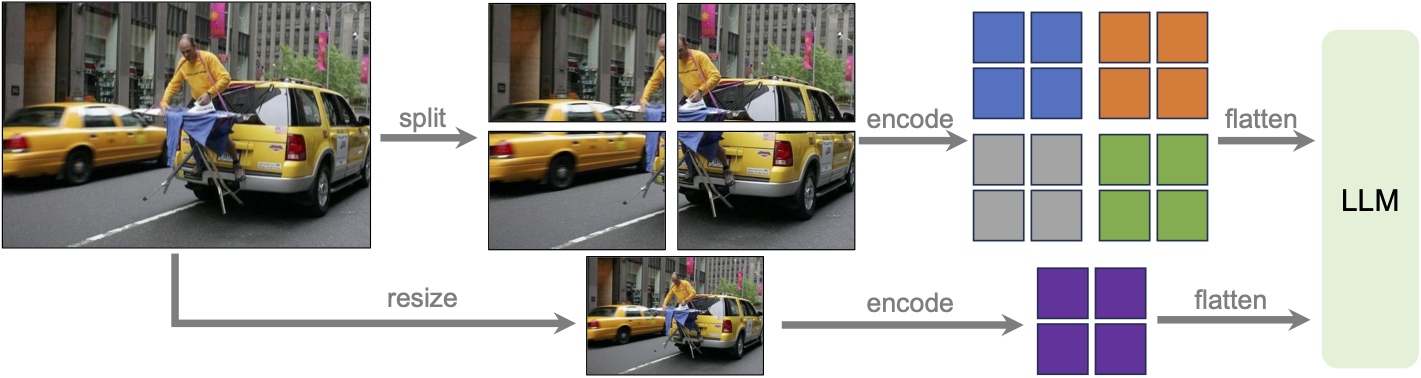
Illustration of dynamic high resolution scheme: a grid configuration of $\\{2 \times 2\\}$
(2) Data Mixture
- High-quality User Instruct Data. Our definition of high-quality visual instruction-following data hinges on two principal criteria: First, the diversity of task instructions, ensuring adequately represent a broad spectrum of user intents that are likely to be encountered in real-world scenarios, particularly during the model’s deployment phase. Second, the superiority of responses is critical, with the objective of soliciting favorable user feedback. To achieve this, we consider two data sources: (1) Existing GPT-V data. LAION-GPT-V and ShareGPT-4V. (2) To further facilitate better visual conversation for more scenarios, we collect a small 15K visual instruction tuning dataset covering different applications. The instructions and images come from LLaVA demo, which are real-world users requests. We carefully filter samples that may have privacy concerns or are potentially harmful, and generate the response with GPT-4V.
- Multimodal Document/Chart Data. (1) We remove TextCaps from our training data as we realize that TextCaps uses the same set of training images as TextVQA. This allows us to better understand the zero-shot OCR capability of our model when evaluating TextVQA during development. To maintain and further improve our model’s OCR capability, we replace TextCaps with DocVQA and SynDog-EN. (2) Motivated by Qwen-VL-7B-Chat, we further add ChartQA, DVQA, and AI2D for better chart and diagram understanding.
(3) Scaling LLM backbone
In addition to Vicuna-1.5 (7B and 13B), we consider more LLMs, including Mistral-7B and Nous-Hermes-2-Yi-34B. These LLMs possess nice properties, flexible commercial use terms, strong bilingual support and larger language model capacity. It allows LLaVA to support a wider spectrum of users and more scenarios in the community. The LLaVA recipe works well with various LLMs, and scales up smoothly with the LLM up to 34B.
Model Card
| Name | LLaVA-NeXT-7B | LLaVA-NeXT-13B | LLaVA-NeXT-34B | |
|---|---|---|---|---|
| Model Size | Total | 7.06B | 13.35B | 34.75B |
| Vision Encoder | 303.5M | 303.5M | 303.5M | |
| Connector | 21M | 31.5M | 58.7M | |
| LLM | 6.74B | 13B | 34.39B | |
| Resolution | 336 x [(2,2), (1,2), (2,1), (1,3), (3,1), (1,4), (4,1)] | |||
| Stage-1 | Training Data | 558K | ||
| Trainable Module | Connector | |||
| Stage-2 | Training Data | 760K | ||
| Trainable Module | Full model | |||
| Compute (#GPU x #Hours) | 8x20 | 16x24 | 32x30 | |
| Training Data (#Samples) | 1318K | |||
Team
- Haotian Liu: University of Wisconsin-Madison

- Chunyuan Li: Bytedance/Tiktok
 (Part of the work was done at Microsoft Research)
(Part of the work was done at Microsoft Research) - Yuheng Li: University of Wisconsin-Madison
- Bo Li: Nanyang Technological University
 (Work collaborated with ByteDance/TikTok)
(Work collaborated with ByteDance/TikTok) - Yuanhan Zhang: Nanyang Technological University (Work collaborated with ByteDance/TikTok)
- Sheng Shen: University of California, Berkeley

- Yong Jae Lee: University of Wisconsin-Madison
Acknowledgement
- A16Z Open Source AI Grants Program.
- We thank Lianmin Zheng, Ying Sheng, Shiyi Cao for the integration of LLaVA to SGLang.
- This work was supported in part by NSF CAREER IIS2150012, Microsoft Accelerate Foundation Models Research, and Institute of Information & communications Technology Planning & Evaluation(IITP) grants funded by the Korea government(MSIT) (No. 2022-0-00871, Development of AI Autonomy and Knowledge Enhancement for AI Agent Collaboration) and (No. RS-2022-00187238, Development of Large Korean Language Model Technology for Efficient Pre-training).
Related Blogs
- LLaVA-NeXT: Stronger LLMs Supercharge Multimodal Capabilities in the Wild
- LLaVA-NeXT: A Strong Zero-shot Video Understanding Model
- Accelerating the Development of Large Multimodal Models with LMMs-Eval
Citation
@misc{liu2024llavanext,
title={LLaVA-NeXT: Improved reasoning, OCR, and world knowledge},
url={https://llava-vl.github.io/blog/2024-01-30-llava-next/},
author={Liu, Haotian and Li, Chunyuan and Li, Yuheng and Li, Bo and Zhang, Yuanhan and Shen, Sheng and Lee, Yong Jae},
month={January},
year={2024}
}
@misc{liu2023improvedllava,
title={Improved Baselines with Visual Instruction Tuning},
author={Liu, Haotian and Li, Chunyuan and Li, Yuheng and Lee, Yong Jae},
publisher={arXiv:2310.03744},
year={2023},
}
@misc{liu2023llava,
title={Visual Instruction Tuning},
author={Liu, Haotian and Li, Chunyuan and Wu, Qingyang and Lee, Yong Jae},
publisher={NeurIPS},
year={2023},
}