LLaVA-Plus Capabilities enabled by Plug and Learning to Use Skills
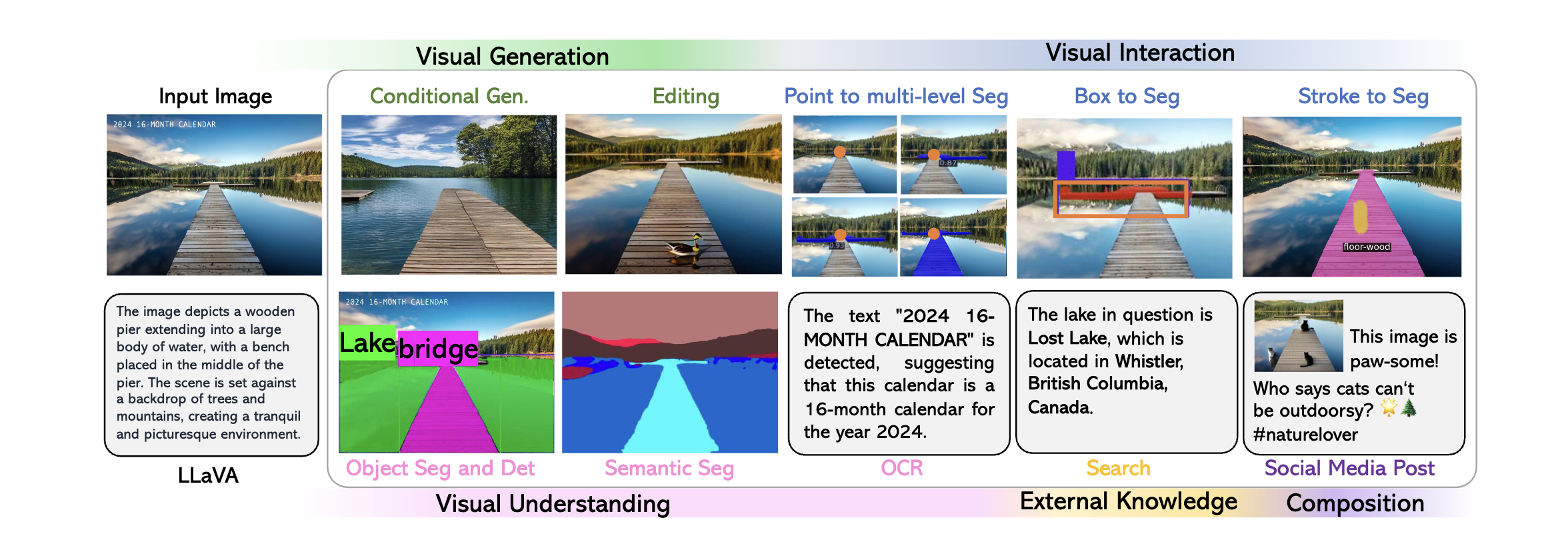
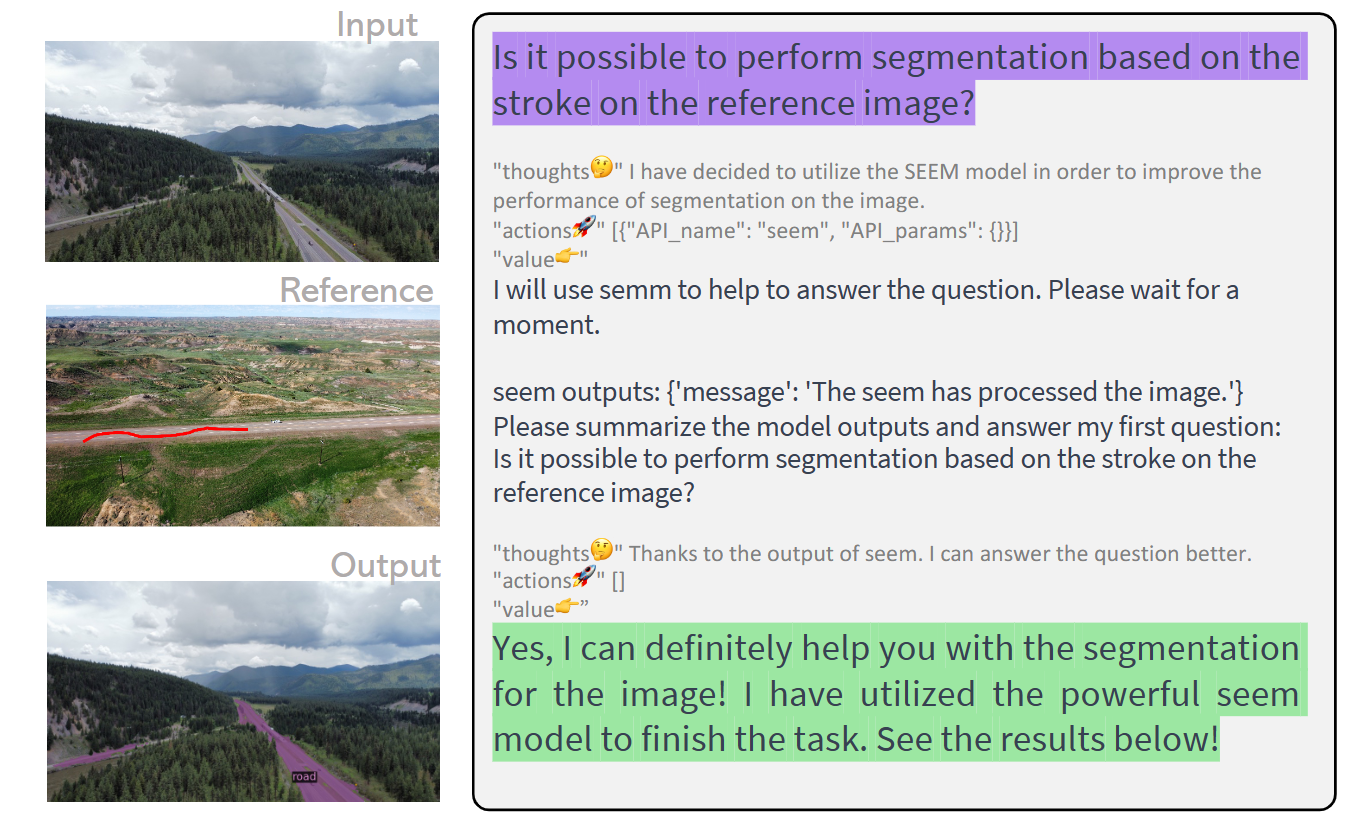
LLaVA-Plus maintains a skill repository that contains a wide range of vision and vision-language pre-trained models (tools), and is able to activate relevant tools, given users’ multimodal inputs, to compose their execution results on the fly to fulfill many real-world tasks.
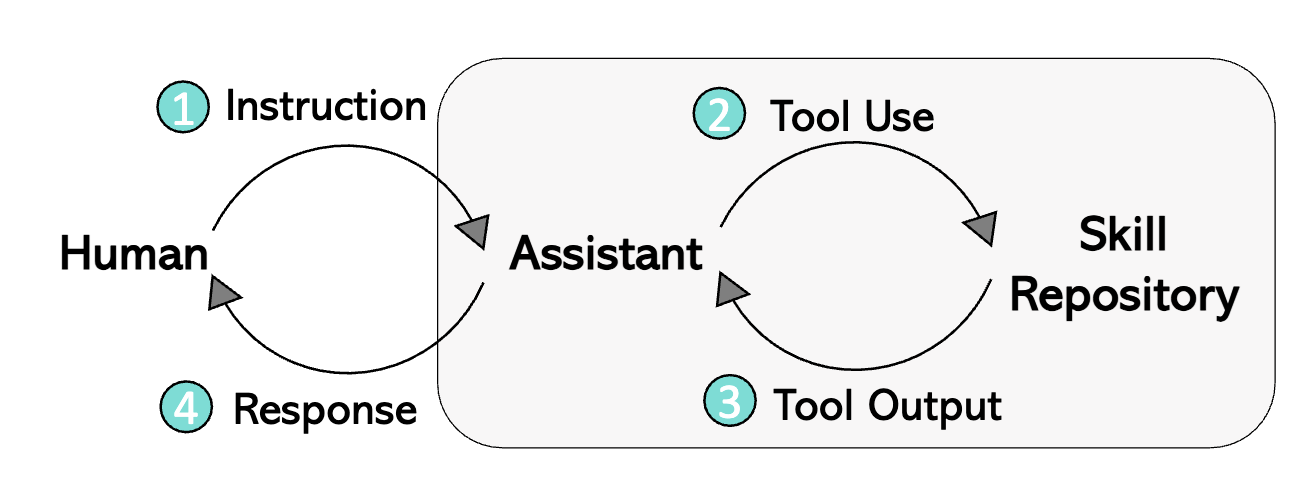
LLaVA-Plus enables tool use with four steps.





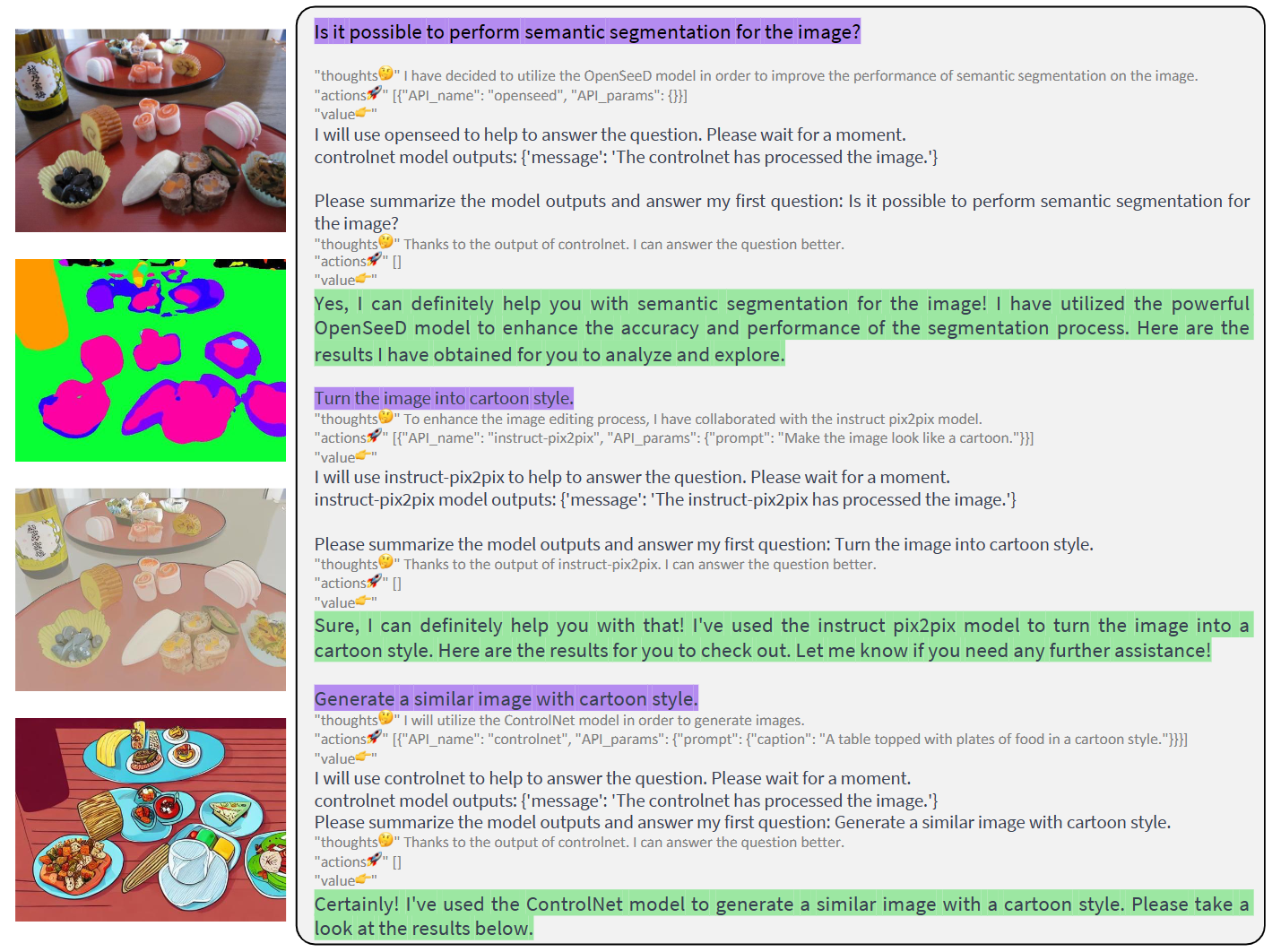


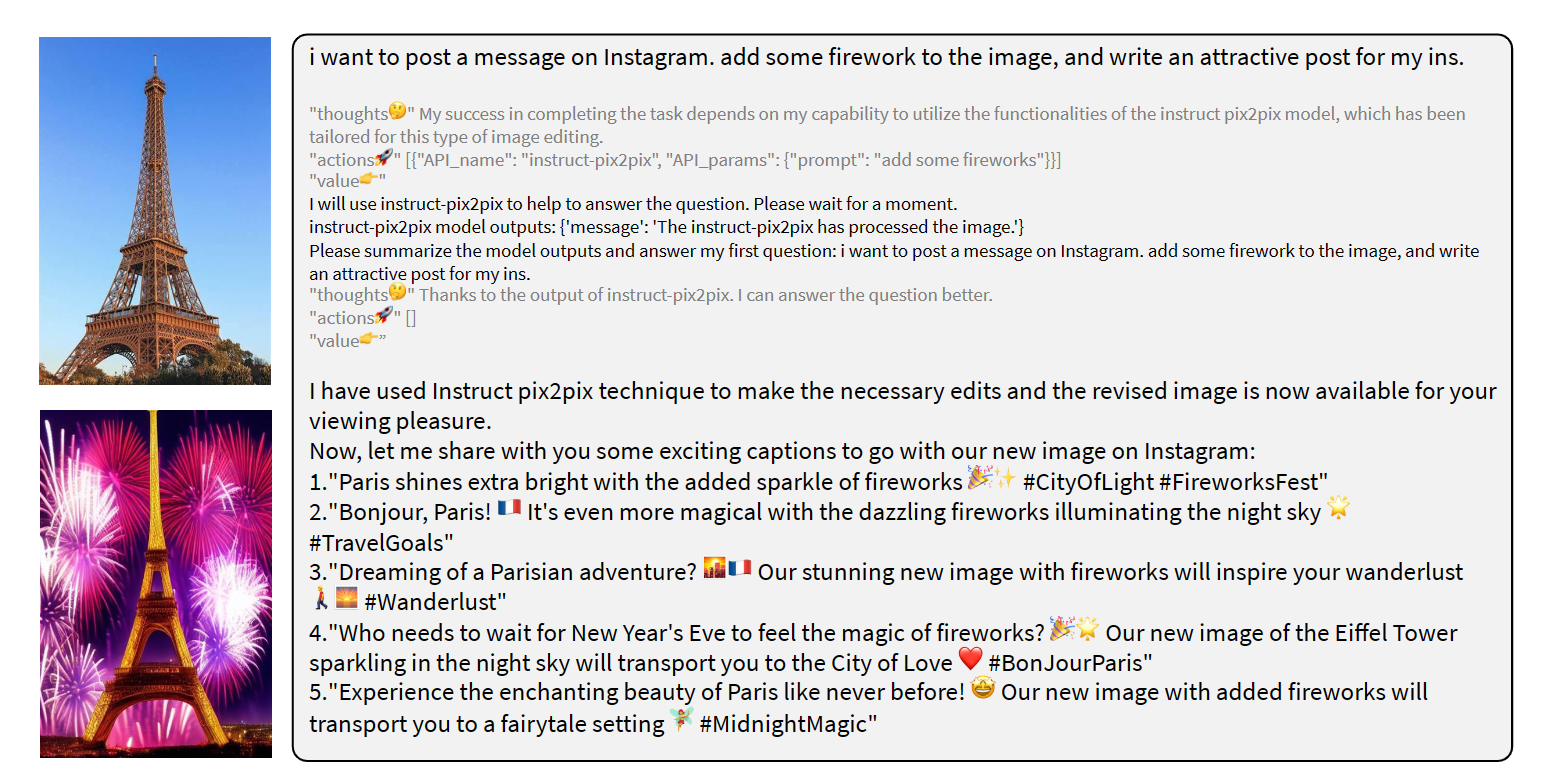

@misc{liu2023llavaplus,
title={LLaVA-Plus: Learning to Use Tools for Creating Multimodal Agents},
author={Shilong Liu and Hao Cheng and Haotian Liu and Hao Zhang and Feng Li and Tianhe Ren and Xueyan Zou and Jianwei Yang and Hang Su and Jun Zhu and Lei Zhang and Jianfeng Gao and Chunyuan Li},
year={2023},
booktitle={arXiv}
}
This website is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. We thank the LLaMA team for giving us access to their models, and open-source projects, including Alpaca and Vicuna.
Usage and License Notices: The data, code and checkpoint is intended and licensed for research use only. They are also restricted to uses that follow the license agreement of LLaVA, CLIP, LLaMA, Vicuna and GPT-4. The dataset is CC BY NC 4.0 (allowing only non-commercial use) and models trained using the dataset should not be used outside of research purposes.
