The rapid advancement of large language models (LLMs) has revolutionized chatbot systems, resulting in unprecedented levels of intelligence as seen in OpenAI's ChatGPT. This success of ChatGPT on language tasks has inspired the community to anticipate a similar success paradigm in the multimodal space, where both language and vision (LV) modalities are involved in the human-machine interaction to unlock many new scenarios, leading to the increasingly popular research topic of building general-purpose assisants. GPT-4V is such an example, taking one step forward to showcase the interesting capabitlies of chatbots with langauge-image input and langauge output. However, despite its impressive performance, GPT-4V is limited in: (1) it is largely a language interaction system, where input images only play the role of providing additional context for chat; (2) the training and architecture details remain unclear, hindering research and open-source innovation in this field.
To demonstrate the new application scenarios of general-purpose assistants in the multimodal space, we introduce LLaVA-Interactive, an open-source demo system, backed by three powerful LV models and an easy-to-use, extensible framework. LLaVA-Interactive is favorable:
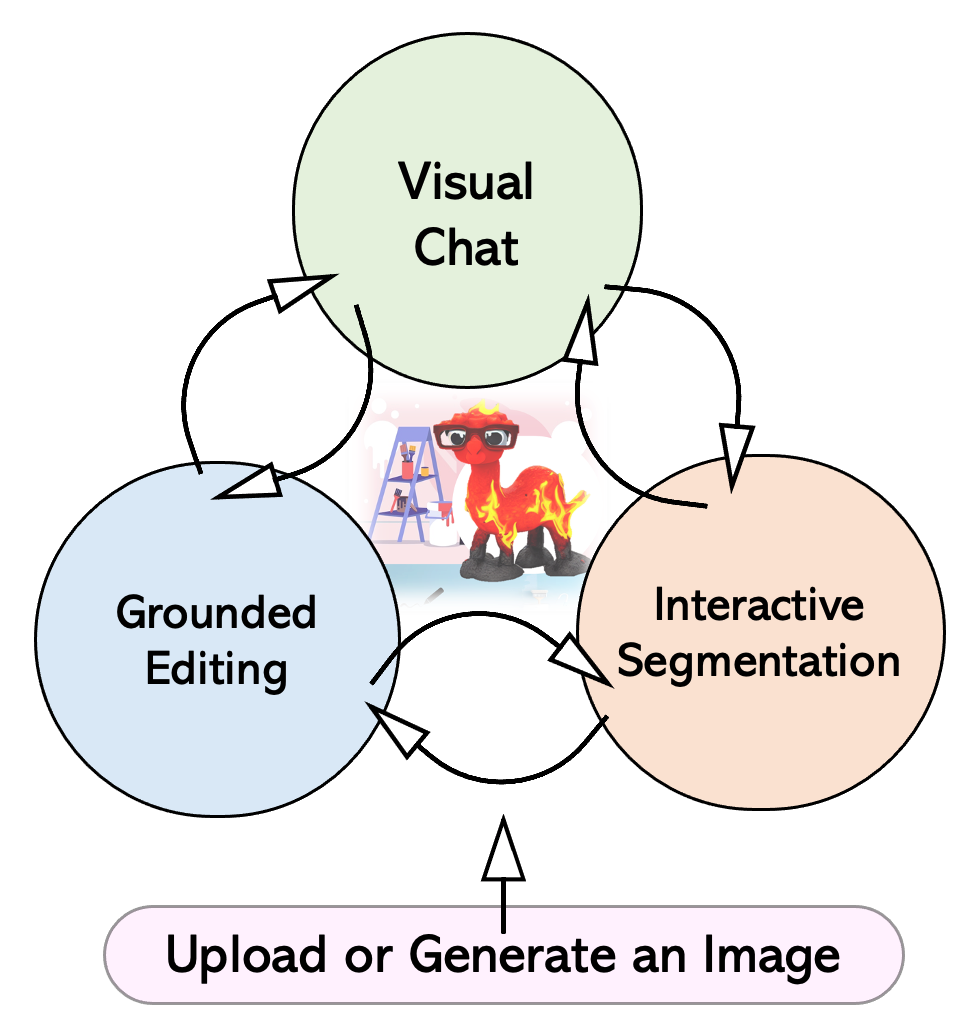
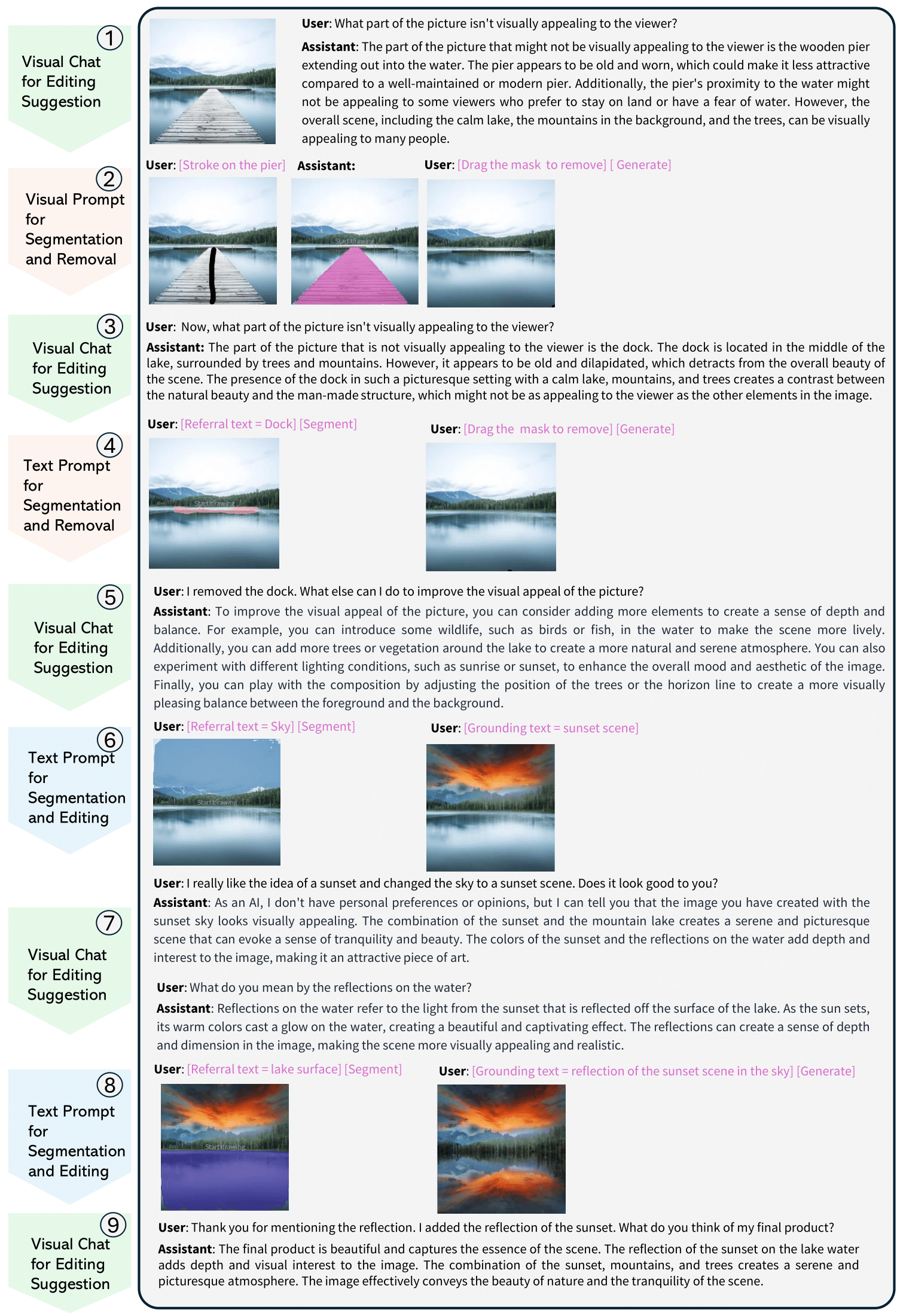
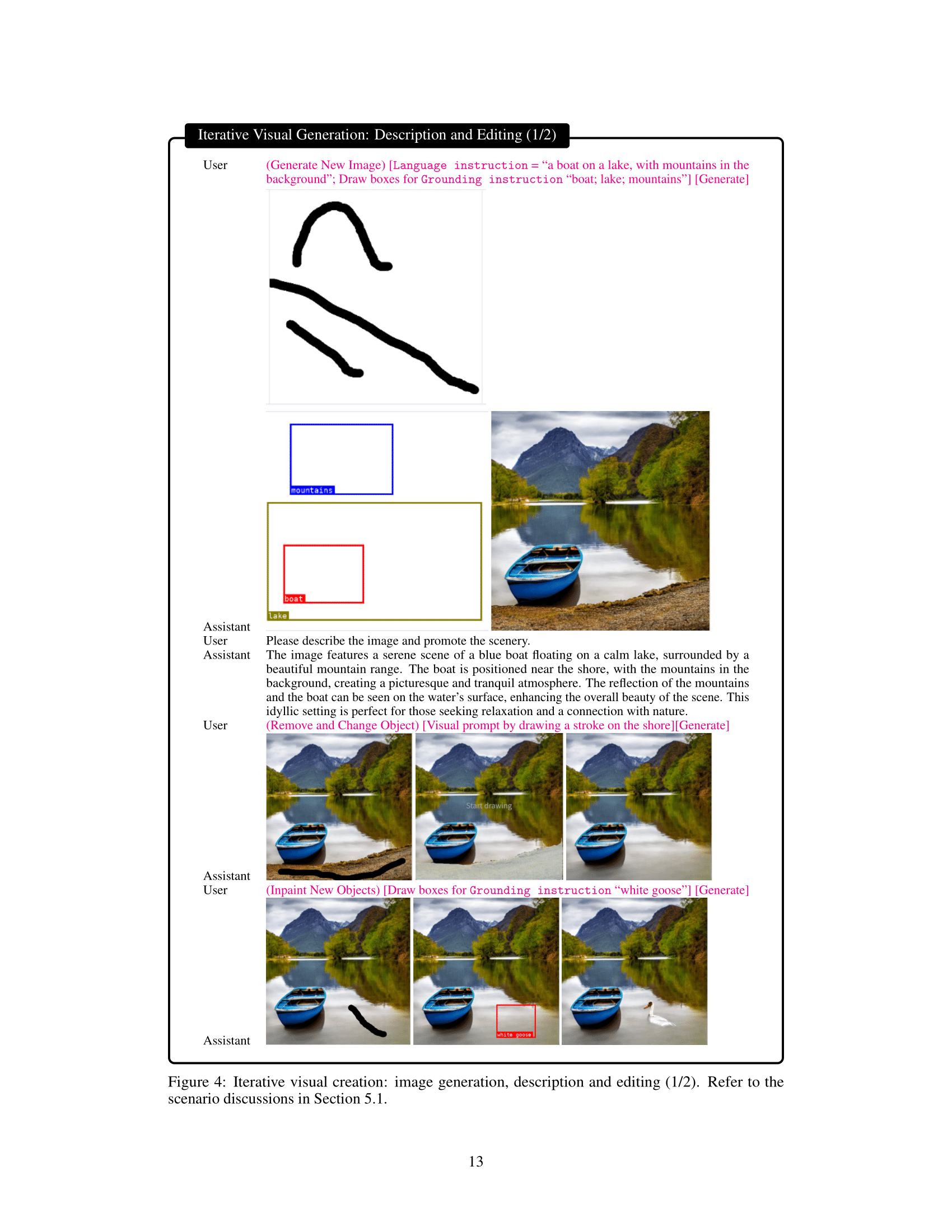
This figure provides a workflow of LLaVA-Interactive. We describe the one typical visual creation process as below:
| System | Visual Input | Visual Output | Visual Interaction |
|---|---|---|---|
| LLaVA / GPT-4V | ✔ | ||
| LLaVA-Interactive | ✔ | ✔ | ✔ |


















@article{liu2023llava,
author = {Chen, Wei-Ge and Spiridonova, Irina and Yang, Jianwei and Gao, Jianfeng and Li, Chunyuan},
title = {LLaVA-Interactive: An All-in-One Demo for Image Chat, Segmentation, Generation and Editing},
publisher = {https://llava-vl.github.io/llava-interactive},
year = {2023}
}
This website is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. We thank the LLaMA team for giving us access to their models, and open-source projects, including Alpaca and Vicuna.
Usage and License Notices: The data, code and checkpoint is intended and licensed for research use only. They are also restricted to uses that follow the license agreement of SEEM, GLIGEN, CLIP, LLaMA, Vicuna and GPT-4. The dataset is CC BY NC 4.0 (allowing only non-commercial use) and models trained using the dataset should not be used outside of research purposes.
