 Multimodal Instrucion-Following Data
Multimodal Instrucion-Following Data
Based on the COCO dataset, we interact with language-only GPT-4, and collect 158K unique language-image instruction-following samples in total, including 58K in conversations, 23K in detailed description, and 77k in complex reasoning, respectively. Please check out ``LLaVA-Instruct-150K''' on [HuggingFace Dataset].
| Data file name | File Size | Sample Size |
|---|---|---|
| conversation_58k.json | 126 MB | 58K |
| detail_23k.json | 20.5 MB | 23K |
| complex_reasoning_77k.json | 79.6 MB | 77K |
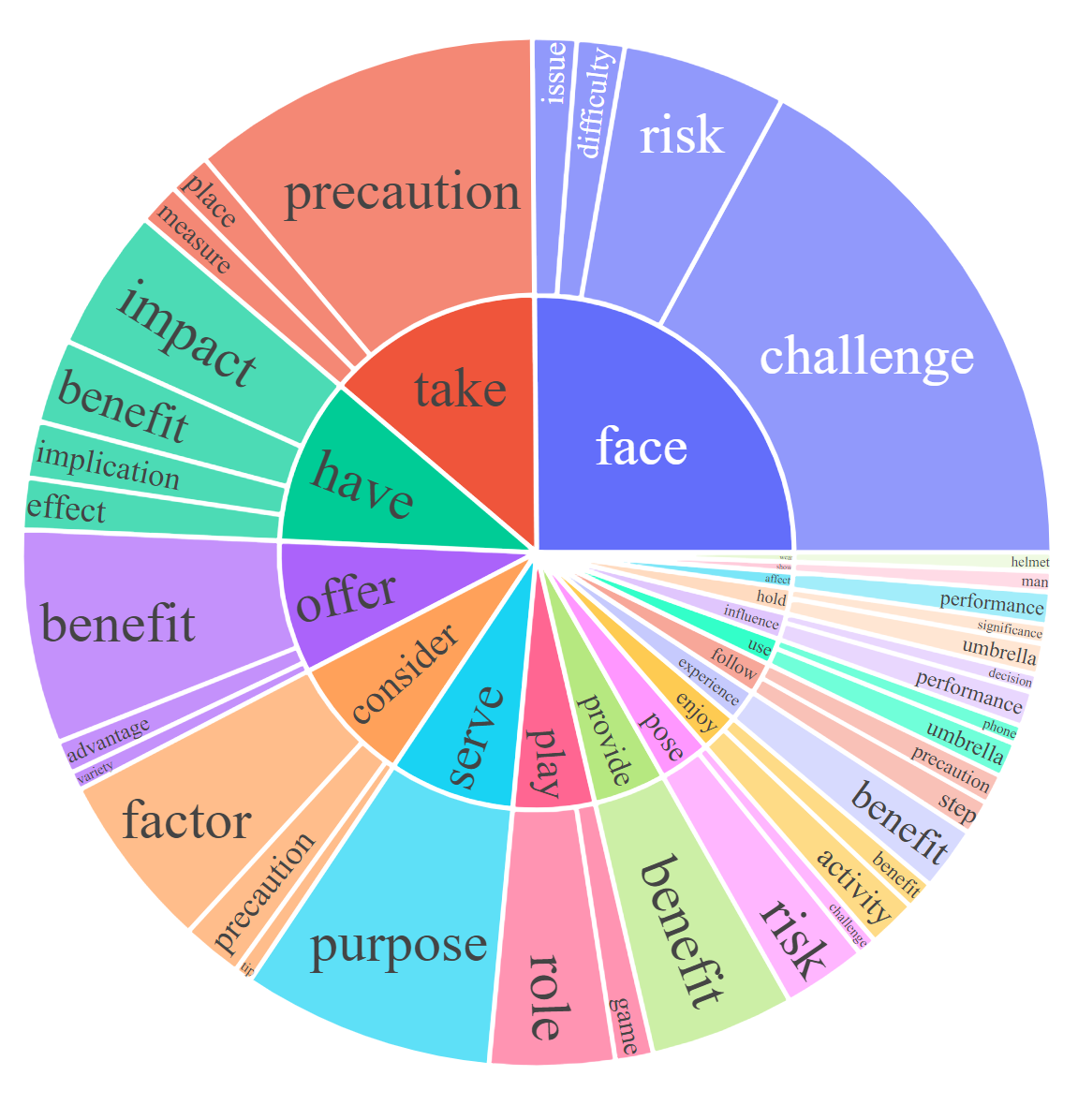
For each subset, we visualize the root noun-verb pairs for the instruction and response. For each chart, please click the link for the interactive page to check out the noun-verb pairs whose frequency is higher the given number.
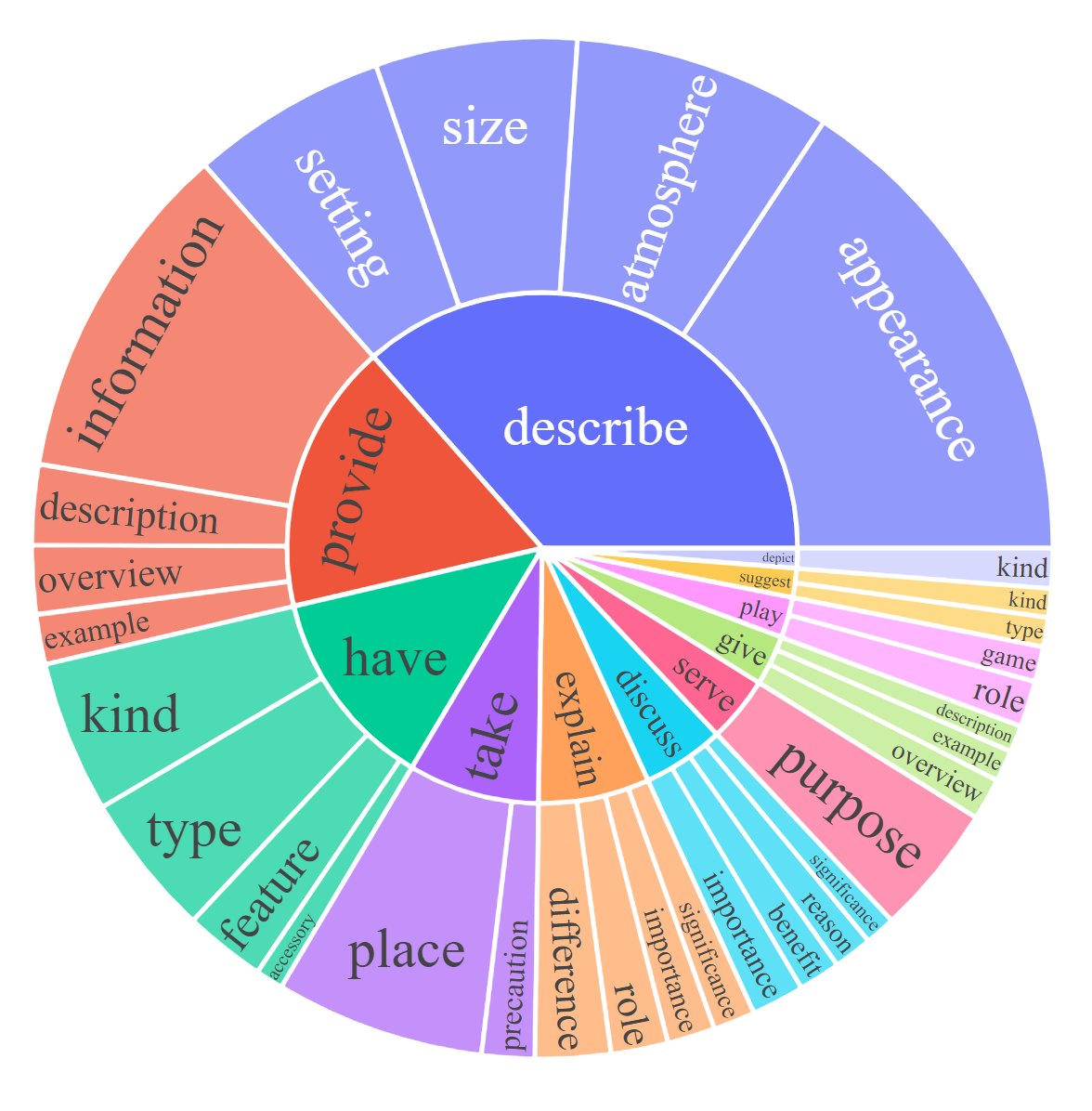
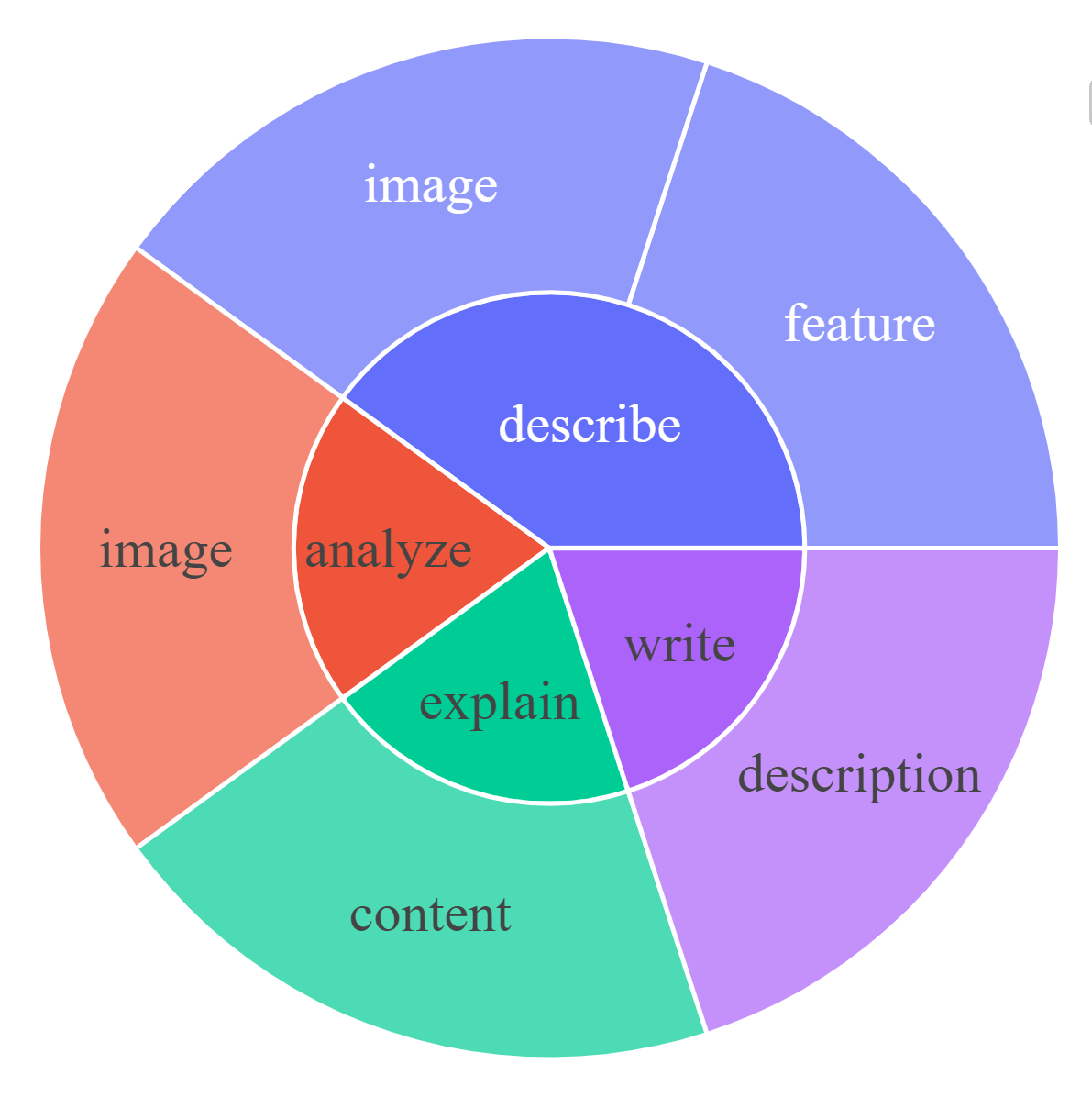
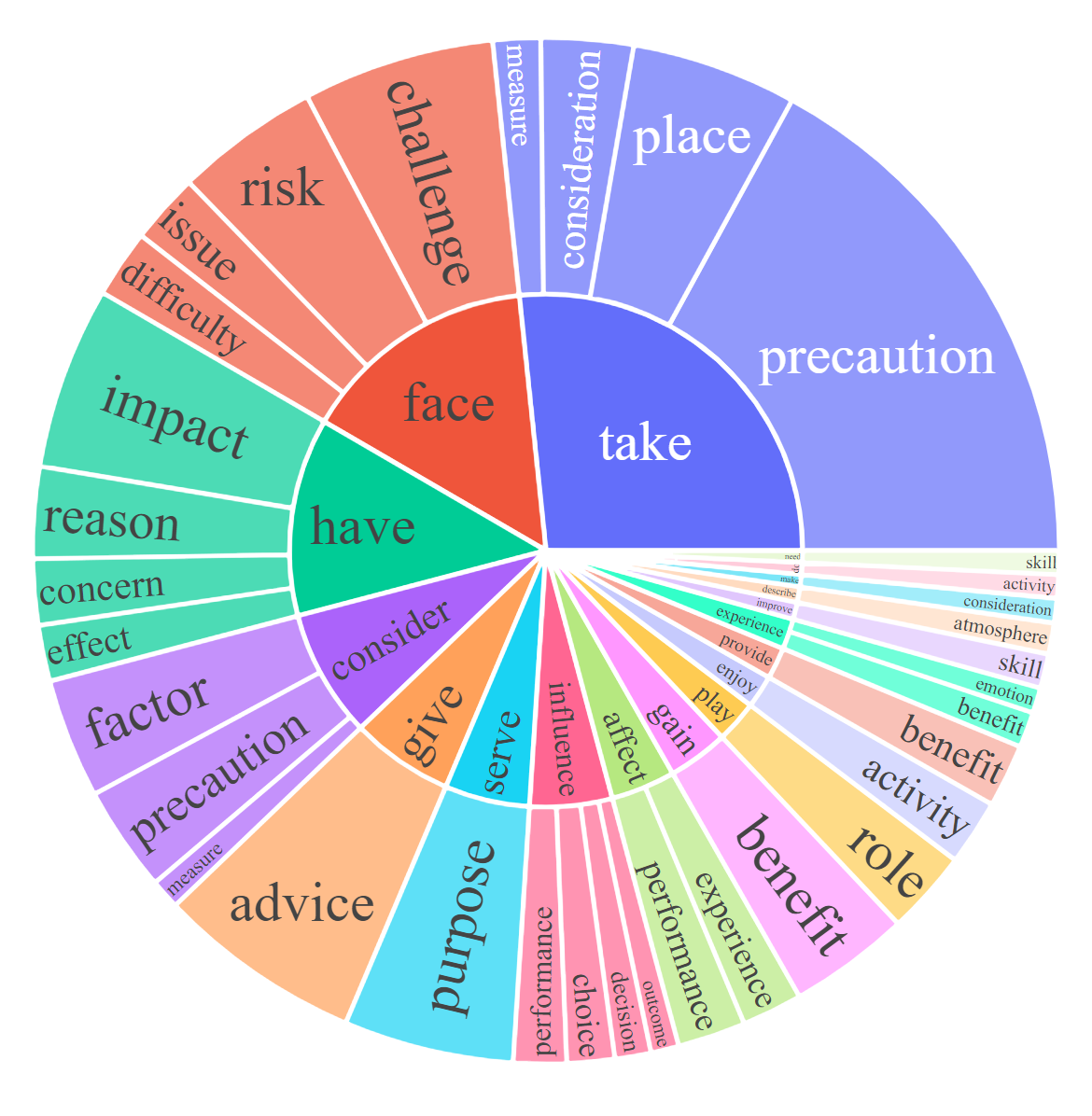
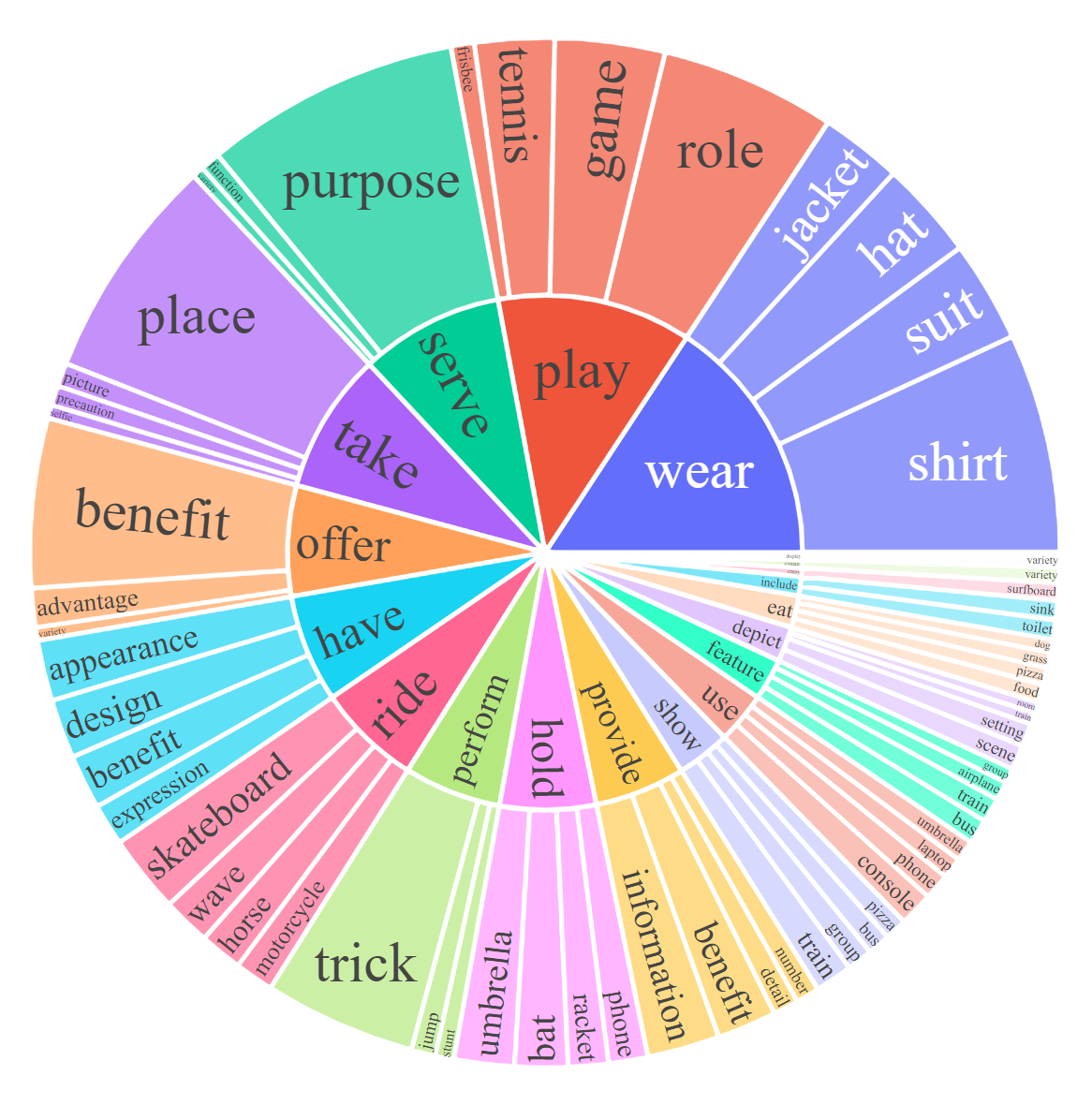

 LLaVA: Large Language-and-Vision Assistant
LLaVA: Large Language-and-Vision Assistant
LLaVa connects pre-trained CLIP ViT-L/14 visual encoder and large language model Vicuna, using a simple projection matrix. We consider a two-stage instruction-tuning procedure:
- Stage 1: Pre-training for Feature Alignment. Only the projection matrix is updated, based on a subset of CC3M.
- Stage 2: Fine-tuning End-to-End. Both the projection matrix and LLM are updated for two different use senarios:
- Visual Chat: LLaVA is fine-tuned on our generated multimodal instruction-following data for daily user-oriented applications.
- Science QA: LLaVA is fine-tuned on this multimodal reasonsing dataset for the science domain.

 Performance
Performance
 Visual Chat: Towards building multimodal GPT-4 level chatbot
Visual Chat: Towards building multimodal GPT-4 level chatbot
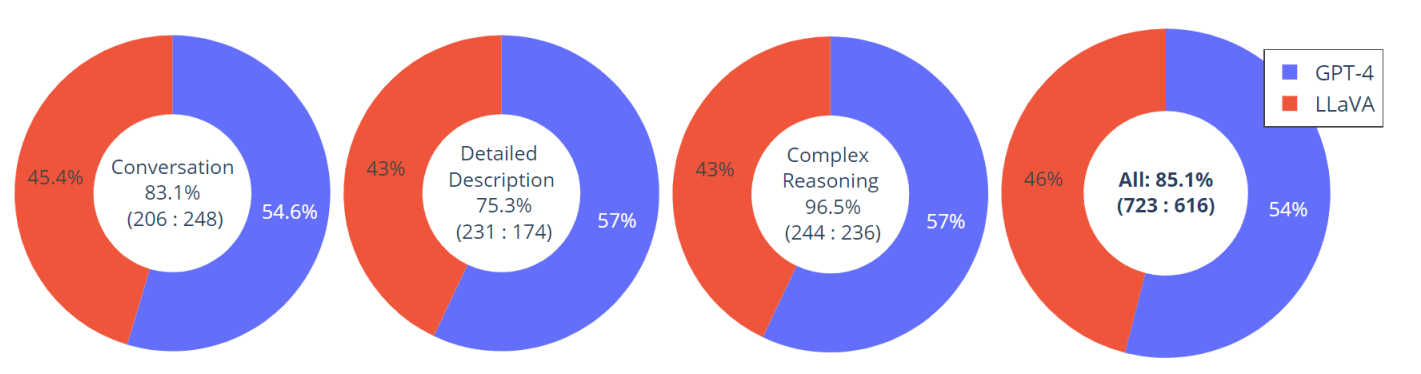
An evaluation dataset with 30 unseen images is constructed: each image is assocaited with three types of instructions: conversation, detailed description and complex reasoning. This leads to 90 new language-image instructions, on which we test LLaVA and GPT-4, and use GPT-4 to rate their responses from score 1 to 10. The summed score and relative score per type is reported. Overall, LLaVA achieves 85.1% relative score compared with GPT-4, indicating the effectinvess of the proposed self-instruct method in multimodal settings
 Science QA: New SoTA with the synergy of LLaVA with GPT-4
Science QA: New SoTA with the synergy of LLaVA with GPT-4
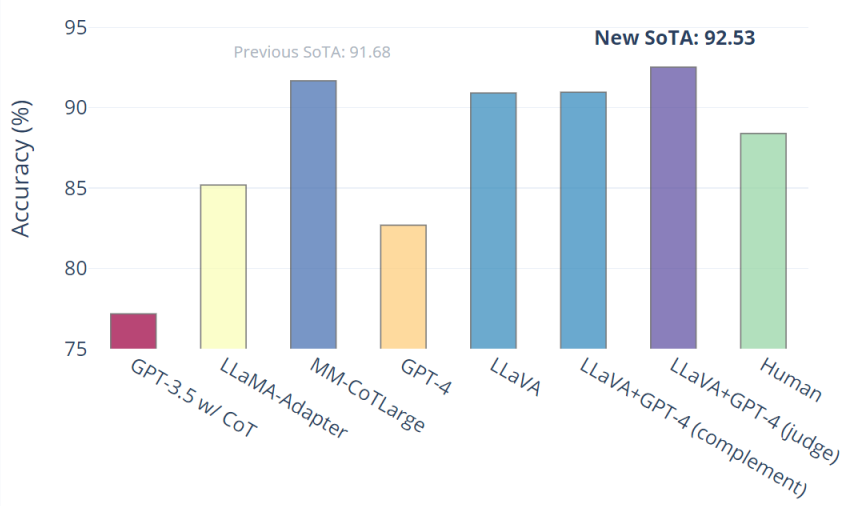
LLaVA alones achieve 90.92%. We use the text-only GPT-4 as the judge, to predict the final answer based on its own previous answers and the LLaVA answers. This "GPT-4 as judge" scheme yields a new SOTA 92.53%.
Examples on Visual Instruction Following
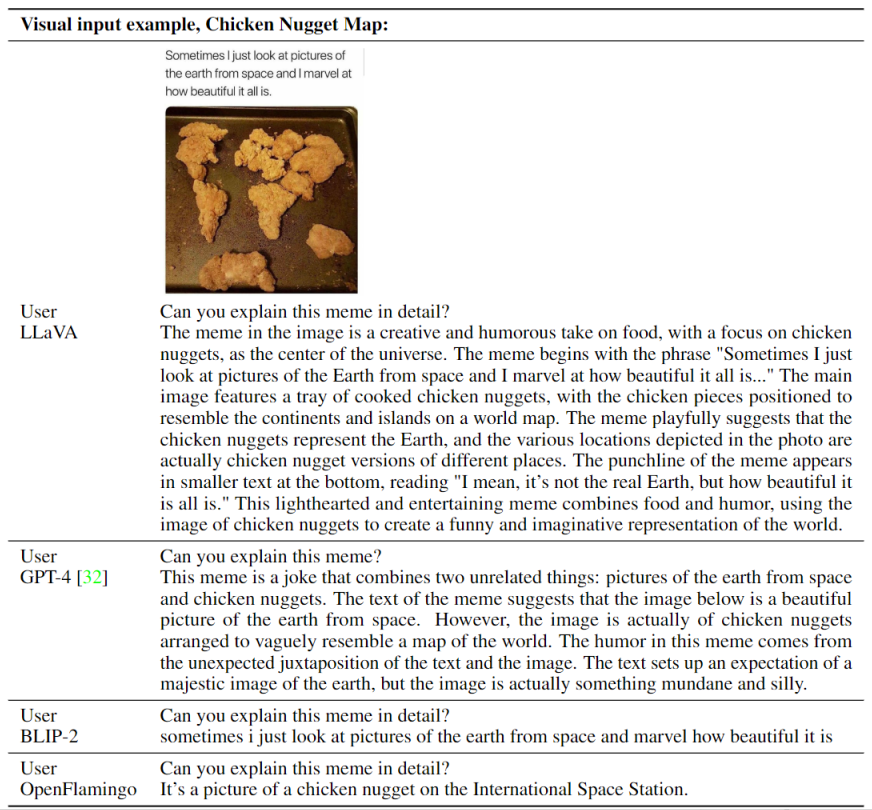
Visual Reasoning on two examples from OpenAI GPT-4 Technical Report

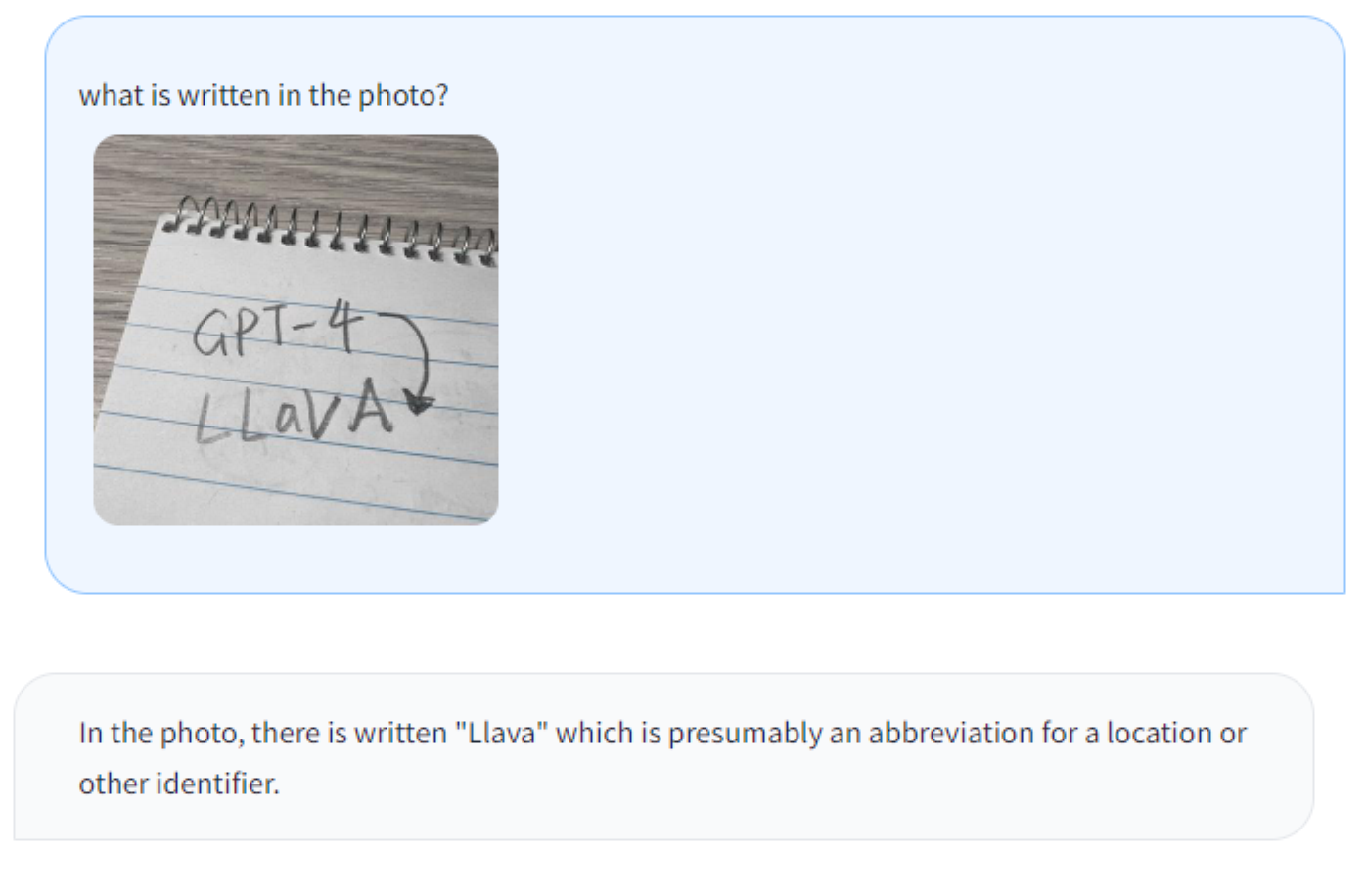
Optical character recognition (OCR)
BibTeX
@misc{liu2023improvedllava,
author={Liu, Haotian and Li, Chunyuan and Li, Yuheng and Lee, Yong Jae},
title={Improved Baselines with Visual Instruction Tuning},
publisher={arXiv:2310.03744},
year={2023},
}
@inproceedings{liu2023llava,
author = {Liu, Haotian and Li, Chunyuan and Wu, Qingyang and Lee, Yong Jae},
title = {Visual Instruction Tuning},
booktitle = {NeurIPS},
year = {2023}
}
Acknowledgement
This website is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. We thank the LLaMA team for giving us access to their models, and open-source projects, including Alpaca and Vicuna.
Usage and License Notices: The data, code and checkpoint is intended and licensed for research use only. They are also restricted to uses that follow the license agreement of CLIP, LLaMA, Vicuna and GPT-4. The dataset is CC BY NC 4.0 (allowing only non-commercial use) and models trained using the dataset should not be used outside of research purposes.
